
Area of Expertise
Performance Tuning
My comprehensive understanding of core performance issues of databases, my Optimization Techniques result in maximizing the speed and efficiency of instances and SQL queries for databases like Oracle, MySQL, PostgreSQL.
Capacity Planning
With a deeper understanding of Capacity Management challenges, my estimation of the object’s growth and storage usages is highly accurate, which improves visibility for the management on resources’ capacity planning and also helps in saving costs.
Backup Strategy
Defining guidelines for organizations and database administrators helps them in devising a backup strategy specific to their environment. My objective is to focus beyond “valid copy of backup” while creating a backup strategy.
Data Security
Focusing on continuous evaluation of the database environment is the key for me to avoid any security lapses introduced in due course of the development lifecycle. Attaching equal importance to the identification of vulnerabilities of the database makes my solution more secure.
Data Modeling
A good data model not only adds flexibility for the developers but also add spices to database performance. My sound expertise of almost two decades on the database makes it easy for me to prepare a best suited, specifically designed data model design for any situations like multi-lingual, data in TBs, Monolithic or Microservice.
SANJEEVA KUMAR
Associate Principal Engineer
Performance Tuning | Database Architect | Data Engineer | DBA
My expertise covers the area of Performance Tuning, Backup Strategy & Database Security on Oracle, PostgreSQL and MySQL databases.
My expertise extends to Capacity Planning, PL/SQL Application development, Data migrations and conversions, Database Migration including Time series & NoSQL databases.
With a deeper understanding of databases, I am Successfully able to convert database-related customer escalations into their appreciations in the quickest time on many occasions. I have worked extensively on statistics & histograms, SQL Plan stability, SQL trace files, Profiler, database instance optimizations, query optimizations, Database modeling, pg_stat_statements, pg_audit, PostGIS, managing tablespaces & storage. Also, successfully orchestrated migration of multi-terabyte database into Production.
I am currently associated with Nagarro Software Pvt Ltd




Associations

Nagarro Software Pvt Ltd, Gurgaon

Polaris Software Lab, Gurgaon

Vayam Technology, NOIDA

Espire Infolabs Pvt Ltd, Gurgaon

Krishna Maruti Ltd, Gurgaon



Blogs

Enabling ARCHIVELOG Mode in Oracle 19c: A Step-by-Step Guide
Introduction ARCHIVELOG mode is a critical configuration for any production Oracle database that requires point-in-time recovery capabilities. In this comprehensive guide, I’ll walk through the process of converting an Oracle 19c database from NOARCHIVELOG to ARCHIVELOG mode, with commands and outputs from a real-world implementation. Why Use ARCHIVELOG Mode? Before diving into the implementation, it’s Read more about Enabling ARCHIVELOG Mode in Oracle 19c: A Step-by-Step Guide[…]

Oracle Database Memory Monitoring Guide
Introduction Database memory management is crucial for maintaining optimal performance in Oracle databases. Inefficient memory usage can lead to slower query execution, increased I/O operations, and poor application response times. This comprehensive guide provides database administrators and developers with practical tools and techniques for monitoring and optimizing Oracle database memory components. Why Memory Monitoring Matters Read more about Oracle Database Memory Monitoring Guide[…]

PostgreSQL Schema Resolution Issues in ETL Processes
Have you ever encountered a frustrating situation where your PostgreSQL function works perfectly when executed directly but fails through your ETL tool? Recently, we faced this exact scenario with our Database (dv_d), and I wanted to share our investigation and solution to help others facing similar issues. This turned out to be a PostgreSQL schema Read more about PostgreSQL Schema Resolution Issues in ETL Processes[…]

Oracle Data Pump Import Date Format Issues: Solving RMAN Way
Introduction Data Pump Import Date Format Issues can bring database migrations to a halt, particularly when dealing with timestamp formats in table creation SQLs like ‘1998-01-01 00:00:00’. Usually this got resolved using setting up NLS_DATE_FORMAT, however, this traditional NLS_DATE_FORMAT solutions might fail, this guide presents a practical RMAN (Recovery Manager) approach to resolve these Data Read more about Oracle Data Pump Import Date Format Issues: Solving RMAN Way[…]

How to Set Up PostgreSQL Read-Only User Permissions
Are you struggling with PostgreSQL read-only user permissions? This step-by-step guide will show you exactly how to create and configure read-only users in PostgreSQL 16. Whether you’re a database administrator or developer, you’ll learn how to properly set up schema-level permissions and avoid common pitfalls. The Challenge: PostgreSQL Read-Only Access Not Working Many developers face Read more about How to Set Up PostgreSQL Read-Only User Permissions[…]
Installing PostgreSQL 16 on RHEL 9: Step-by-Step Guide
PostgreSQL 16 is the latest release of the powerful open-source relational database system, offering enhanced performance, security, and new features. This guide walks you through installing PostgreSQL 16 (for previous version click here) on RHEL 9 with step-by-step instructions, commands, and best practices. Step 1: Update the System Before installing PostgreSQL, update your system packages Read more about Installing PostgreSQL 16 on RHEL 9: Step-by-Step Guide[…]

Generative AI for Databases: Transforming Data Management
Introduction For decades, relational databases have been the backbone of enterprise data management, relying on predefined schemas, manual query optimization, and structured data patterns. However, the emergence of generative AI is fundamentally transforming this landscape. By introducing capabilities like intelligent data synthesis, automated performance tuning, and adaptive query processing, AI is evolving databases from passive Read more about Generative AI for Databases: Transforming Data Management[…]

Creating and Managing the ASMSNMP User in Oracle ASM
Introduction The ASMSNMP user plays a crucial role in Oracle ASM (Automatic Storage Management), primarily enabling monitoring through Oracle Enterprise Manager (OEM) and we learn Creating ASMSNMP User in Oracle ASM. In this guide, we’ll cover: This step-by-step guide ensures your ASM environment is properly monitored while following Oracle best practices. Understanding ASMSNMP in Oracle Read more about Creating and Managing the ASMSNMP User in Oracle ASM[…]

PostgreSQL Configuration Parameters: Best Practices for Performance Tuning
Introduction PostgreSQL configuration parameters play a crucial role in optimizing database performance. PostgreSQL is a powerful and flexible database, but its default configuration isn’t always optimal for production workloads. Performance tuning requires adjusting key PostgreSQL configuration parameters based on hardware resources, workload type, and concurrency needs. In this guide, we’ll cover:✅ Important PostgreSQL 16 parameters Read more about PostgreSQL Configuration Parameters: Best Practices for Performance Tuning[…]

How to Increase Swap Size in Linux: A Complete Guide
Introduction Managing swap space efficiently is essential for optimal Linux performance, especially when handling memory-intensive applications. Sometimes, Oracle databases or Oracle Enterprise manager or any other application which is asking for swap will fail installations. This guide covers three common scenarios to Increase swap size in Linux: Follow these step-by-step instructions to optimize your system’s Read more about How to Increase Swap Size in Linux: A Complete Guide[…]

Resolving Pluggable Database (PDB) Opening in RESTRICTED MODE (ORA-65177) in Oracle 19c
Introduction Encountering, ORA-65177 ,a Pluggable Database (PDB) that opens in RESTRICTED mode can cause operational challenges, especially when working in a multitenant environment. This issue is often linked to synchronization failures between the Container Database (CDB) and its associated PDBs. We will delve into the root cause of the problem and provide a step-by-step resolution. Read more about Resolving Pluggable Database (PDB) Opening in RESTRICTED MODE (ORA-65177) in Oracle 19c[…]

Mastering PSQL: Enable Timings and Fetch All Rows Without Paging
PostgreSQL’s interactive terminal, psql, is an incredibly powerful tool for managing databases and executing queries. In this blog, we’ll discuss how to measure query execution time using “timing” and fetch all rows of a query result without paging using “\pset pager off”`. Let’s dive in step-by-step. Why Enable Timing in PSQL? When optimizing your SQL Read more about Mastering PSQL: Enable Timings and Fetch All Rows Without Paging[…]

From Regulation to Responsibility: Understanding the EU’s AI regulation
Introduction Artificial Intelligence (AI) has rapidly transformed various aspects of our lives, from personalized recommendations to autonomous vehicles. However, with great power comes great responsibility. The European Union (EU) recognizes the need to strike a balance between fostering AI innovation and safeguarding fundamental rights. On March 13, 2024, the EU took a significant and bold step Read more about From Regulation to Responsibility: Understanding the EU’s AI regulation[…]

The World of Generative AI: An Introductory Exploration
Generative AI! If you’ve ever marveled at a piece of artwork created by an AI, or interacted with a chatbot that seemed almost human, then you’ve already had a glimpse into what Generative AI can do. Welcome to this fascinating world of Gen AI! Generative AI is a subset of artificial intelligence that focuses on Read more about The World of Generative AI: An Introductory Exploration[…]

Optimizer Access Paths: index unique scan
In our previous blog, we have talked about the optimizer access path. In the last few blogs, we have explained different access paths. In this blog, we will see how the index unique scan works. Index unique scan is the optimizer access path where the database returns at most one row. It reads the index Read more about Optimizer Access Paths: index unique scan[…]
Optimizer Access Paths : Fast Full Scan
An index fast full scan reads the entire index as it is i.e. as it exists on the disk. This index read is unsorted. This access path usage multiblock IO to perform the index scan. Index fast full scan simply reads all of the leaf, branch and root block of index quickly using multiblock IO Read more about Optimizer Access Paths : Fast Full Scan[…]

Data Replication Setup Using Master and Slave: PostgreSQL- IV
This is last and final blog on Master-Slave replication in PostgreSQL database. In last blog, we have seen Async node setup. We are exploring Sync node in this blog. We will use the same automation script for Sync node also with two changes in master and one change in slave configuration. Let’s start with master. Read more about Data Replication Setup Using Master and Slave: PostgreSQL- IV[…]
Data Replication Setup Using Master and Slave: PostgreSQL- III
In last few blogs, we have seen how to automate steps required to setup Master-slave nodes. This blog would be the last in this series. Until now we have discussed how the architecture should look like and what parameters are needed to be modified to what value on master and slave node. In this blog, Read more about Data Replication Setup Using Master and Slave: PostgreSQL- III[…]

PostgreSQL Meta-Command using psql: Command Information -IV
This is in continuation of My last blog about Meta Commands in PostgreSQL. In last blog I have explained what a Meta command and how to list databases. In next few blogs we will explore few of Meta commands. Lets start exploring schemas. Visit this series of last blog for other command. The command we Read more about PostgreSQL Meta-Command using psql: Command Information -IV[…]
Data Replication Setup Using Master and Slave: PostgreSQL – I
In last few blogs, we have seen how to automate steps required to setup Master-slave nodes. In next few blogs we will explore how High Availability(HA) will be setup. In this blog we will talk about how the architecture look like. To achieve HA in the PostgreSQL database, we should setup a Master-Slave replication environment Read more about Data Replication Setup Using Master and Slave: PostgreSQL – I[…]
Data Replication Setup Using Master and Slave: PostgreSQL – II
In last few blogs, we have seen how to automate steps required to setup Master-slave nodes. In next few blogs we will explore how High Availability(HA) will be setup. We can implement this master-slave environment on separate VMs. We can also implement this on the same machine. For blogging purposes, we will use the same machine for Read more about Data Replication Setup Using Master and Slave: PostgreSQL – II[…]
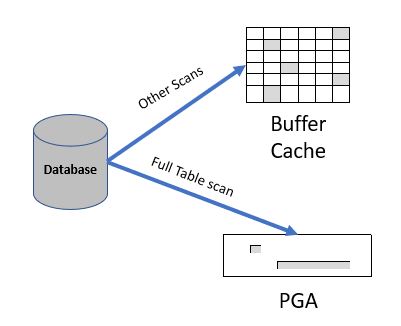
Optimizer Access Paths : Direct Path Read
In usual business, Oracle reads data from data files into the buffer cache of SGA. A Read request is served from there to the client. However, A direct path read is where the data is read directly from the data files into the PGA rather than into the buffer cache in the SGA. Direct Path Read more about Optimizer Access Paths : Direct Path Read[…]
Optimizer Access Paths : What is Index Full Scan
Index full scan is the optimizer access path where the database reads the index from start to end, one block at a time. It reads the index starting from the root block, navigating down using branch towards the left side, or right side if we are doing a descending full scan until it hits the Read more about Optimizer Access Paths : What is Index Full Scan[…]
Automating Master and slave replication: PostgreSQL – I
Master-slave replication setup is the implementation of HA in PostgreSQL. Deployment architecture of 1 master and at least one slave in SYNC mode would be able to provide senses of High Availability of the database. To achieve this we require some steps to be performed into the database which will make one of the nodes Read more about Automating Master and slave replication: PostgreSQL – I[…]
MVCC Concurrency Architecture: PostgreSQL way of implementation – III( pros/cons)
We have explored the PostgreSQL implementation of MVCC in the last two blogs. We will understand the pros and cons of this way of implementation in this blog. This implementation avoided the need for locking of a tuple for any possible updates because the updates are not in-place. Updates in PostgreSQL are creating a complete Read more about MVCC Concurrency Architecture: PostgreSQL way of implementation – III( pros/cons)[…]
PostGIS Installation with PostgreSQL
PostgreSQL supports many other tools in form of database extensions like UUID support, dblink. In the same way, it also supports geographic and spatial data with help of PostGIS. This blog will explain how to install PostGIS 2.5 which can be used by PostgreSQL 11. There are many version of this spatial extension of database Read more about PostGIS Installation with PostgreSQL[…]
What is a Database Cluster: PostgreSQL
In the last blog, we have installed PostgreSQL on different Linux platforms ( CentOs, Ubuntu). However, We have leftover to initialize the installation and connection to the database that we will discuss here. Postgres provides more than one way to initialize a database cluster. We will use pg_createcluster in this blog. But before that, we Read more about What is a Database Cluster: PostgreSQL[…]
PostgreSQL Meta-Command using psql: Command Information -III
This is in continuation of My last blog about Meta Commands in PostgreSQL. In last blog I have explained what a Meta command and how to list databases. In next few blogs we will explore few of Meta commands. Lets start exploring schemas. Visit this series of last blog for other command. The command we Read more about PostgreSQL Meta-Command using psql: Command Information -III[…]
PostgreSQL Meta-Command using psql: Command Information -II
This is in continuation of My last blog about Meta Commands in PostgreSQL. In last blog I have explained what a Meta command is all about. In next few blogs we will explore few of Meta commands. Lets start exploring databases. The command we will explore here is:1. \l2. \c Once you connected to a Read more about PostgreSQL Meta-Command using psql: Command Information -II[…]
Optimizer Access Paths: How Index FFS works with Distinct
Distinct is the keyword that oracle used to filter out unique values from a column. However, it is very interesting to see the behavior followed by the optimizer for its access path. In this “Optimizer Access Paths” blog, we will see how we can make optimizer to use an index with a distinct keyword. Let’s Read more about Optimizer Access Paths: How Index FFS works with Distinct[…]
MVCC Concurrency Architecture: PostgreSQL way of implementation – II
This is in continuation from my last blog on PostgreSQL implementation of MVCC. We will understand transaction id (XID), versioning of a tuple (xmin & xmax) in more detail. Before we move to understand the implementation of a transaction using MVCC, let’s first understand how a tuple is created/updated/deleted. PostgreSQL assigns the current transaction id Read more about MVCC Concurrency Architecture: PostgreSQL way of implementation – II[…]
Optimizer Access Paths: How oracle database works
In this blog, we will explore what is the access path in the Oracle database. However, before moving to the access path, let’s first understand what is a row source. It is a set of rows that are returned in a step by execution plan. It can be a table or a result of join operations Read more about Optimizer Access Paths: How oracle database works[…]
Concurrency Control in PostgreSQL
In previous blog, we have detailed out about the inception of PostgreSQL. In this blog, we will explain the architecture (MVCC) with respect to PostgreSQL. Concurrency Control: There are more than one way to provide concurrency control by database. Concurrency is an important factor to allow many users to work on the same dataset at Read more about Concurrency Control in PostgreSQL[…]
PostgreSQL Meta-Command using psql: Command Information -I
This is in continuation of My last blog about Meta Commands in PostgreSQL. In last blog we have explained what a Meta command is all about. In next few blogs we will explore few of Meta commands. Let’s start with psql command itself. Once we logged in using psql, the environment should be look like Read more about PostgreSQL Meta-Command using psql: Command Information -I[…]

How To: List keys of collection MongoDB
There are many things needed in the DBA’s life for which there are no simple and straight forward ways to find out and they sometimes are tricky to find out. One of them is to find the keys of a collection. There are alternate methods we can certainly explore to retrieve all keys. the catch Read more about How To: List keys of collection MongoDB[…]
PostgreSQL Meta-Command using psql: Generic Information
In our last blog we have discussed the history of origination of PostgreSQL database. This database, like all other RDBMS, has more than one interface to connect to the database. PostgreSQL has psql program as command line interface (CLI) and PgAdmin as graphical user interface (GUI) psql as complete set of commands through which we Read more about PostgreSQL Meta-Command using psql: Generic Information[…]
PostgreSQL Installation on CentOS 7
There are multiple ways of installation of the PostgreSQL database on Unix like platforms. We will explore the installation of PostgreSQL version 12 on CentOS 7 using YUM installation. Let’s start. Verifying the version of CentOS: root@localhost yum.repos.d]# rpm -q centos-release centos-release-7-7.1908.0.el7.centos.x86_64 PostgreSQL allows us to download many version across multiple platform, one should visit its official Read more about PostgreSQL Installation on CentOS 7[…]
PostgreSQL Installation on Ubuntu
There are multiple ways of installation of the PostgreSQL database on Unix like platforms. We will explore the installation of PostgreSQL version 11 on Ubuntu 18.04 LTS using apt installation. Let’s start. Login to Ubuntu and check the version of Ubuntu. postgres@sanjeeva:/home/sanjeeva/postgres$ lsb_release -a No LSB modules are available. Distributor ID: Ubuntu Description: Ubuntu 18.04.5 LTS Release: Read more about PostgreSQL Installation on Ubuntu[…]
Evolvement of PostgreSQL: Background
Research papers of “System R” from IBM were initially picked up by two professors, Michael Stonebraker and Eugene Wong, at Berkeley University, California. This resulted in a new database called INteractive Graphics REtrieval System i.e. “Ingres“. The work done by this duo for Ingres becomes the foundation of many relational databases like MS SQL Server, Read more about Evolvement of PostgreSQL: Background[…]
How To: List all indexes in MongoDB
Indexes are a very important structure in any database and the same is true with MongoDB as well. It adds spices to the performance of your query. It is also very important to know what and how many indexes are created on your DB. In the normal life of DBA, one needs to find out Read more about How To: List all indexes in MongoDB[…]
How To: Creating a collection subset from collection in MongoDB
Many a time there are required to create a new collection from existing ones with the same or different size. In this blog, we will see how to create a new collection from the existing one and with a smaller size. For Sample data, We may use Kaggle to get huge data set. In my collection, I Read more about How To: Creating a collection subset from collection in MongoDB[…]

InfluxDB: How to perform Quick cluster installation on CentOS
This is second part of my installation blog on InfluxDB. In the First part of this blog we have discussed single instance installation. In this part we are going to discuss cluster installation for InfluxDB. For cluster installation which is not a production ready system InfluxDB provides a special cluster installation package which they called Read more about InfluxDB: How to perform Quick cluster installation on CentOS[…]
InfluxDB: How to perform a single node installation on CentOS
Among many Time Series databases (TSDB), InfluxDB is able to secure its position in the market. This is because InfluxDB provides many features that give added advantages and make it sustainable in various scenarios. Besides these, it also provides easy installation and configuration. InfluxDB gives flexibility to the user to install a single instance, QuickStart Read more about InfluxDB: How to perform a single node installation on CentOS[…]
Time Series Database : Evolvement
Rapid growth of sensor-based, IoTs, social media, financial data like stock market activities and many other information streaming platforms created opportunity to design a whole new database which can capture streaming information with highlighting the importance of time into it. This is so because even traditional RDBMS was not able to efficiently handle complex business Read more about Time Series Database : Evolvement[…]
Cloud database war: Advantage shifting to Red?
With its inception in 2006, Amazon AWS has definitely gone a long way. Engineers from Amazon worked really-really well which has not only completely changed the horizon of cloud but also emerges as one of the boon for any business to adopt. Although, there are many other vendors available in the cloud market and they Read more about Cloud database war: Advantage shifting to Red?[…]

WiredTiger: A game changer for MongoDB
Storage engine is one of the key component of any database. It is, in fact, a software module which is used by database management system to perform all storage related operations e.g. create information, read information and update any information. The term storage means both disk storage and memory storage. Choosing right storage engine is Read more about WiredTiger: A game changer for MongoDB[…]

Drop a database
There are times when you require to drop your existing database for more than one reason. Dropping a database is not a tough job at all, if you are very sure that which database you should drop. Problem Statement: How to drop database. Status or mode of database in which it can be dropped Step Read more about Drop a database[…]

Data Pump: impdp
Problem Statement: Restore entire database using Data Pump. Restore table(s) Restore tablespace(s) Restore schema(s) Restore using Transportable tablespaces (TTS) Restore from multiple small sizes of dump files Restore in parallel mode Approach: There are single shot solution to all the above problem statement and it is IMPDP in Data Pump. It is one of various Read more about Data Pump: impdp[…]

Trend of data growth in Oracle Database
In real production world “Prediction” of data growth is an important aspects of DBA life because this will allow business not only to foresee the real position in terms of existing hardware but also enable to plan the future expenses which should be spent on hardware(s) & storage. To generate data growth report, Oracle provides Read more about Trend of data growth in Oracle Database[…]
Oracle Data Pump: expdp & impdp
Problem Statement: Backup entire database using Data Pump. Backup table(s) Backup tablespace(s) Backup schema(s) Backup using Transportable tablespaces (TTS) Generate multiple small sizes of dump files Backup in parallel mode Approach: There are single shot solution to all the above problem statement and it is Data Pump. It is one of various backup tools provided Read more about Oracle Data Pump: expdp & impdp[…]
Data Pump: a tool to backup and restore database
Among various techniques of backing up your database Oracle provides data pump as one of tool which they are constantly improving and making this tool sharper release by release. Since its first launch with 10g version, it has improved a lot not only in terms of its new features but in terms of performance as Read more about Data Pump: a tool to backup and restore database[…]
MongoDB Enterprise Edition Installation – Ubuntu
MongoDB is one of the document oriented open source database developed in c++, first come into shape in 2007 when in order to overcome the shortfall of existing database while working for an advertising company “DoubleClick” development team has decided to go further rather than struggling with database. The team of this advertising company was Read more about MongoDB Enterprise Edition Installation – Ubuntu[…]
How to: Uninstallation of MongoDB on Ubuntu
MongoDB is one of the document oriented open source database developed in c++, first come into shape in 2007 when in order to overcome the shortfall of existing database while working for an advertising company “DoubleClick” development team has decided to go further rather than struggling with database. The team of this advertising company was Read more about How to: Uninstallation of MongoDB on Ubuntu[…]
MongoDB Installation – Ubuntu
MongoDB is one of the document oriented open source database developed in c++, first come into shape in 2007 when in order to overcome the shortfall of existing database while working for an advertising company “DoubleClick” development team has decided to go further rather than struggling with database. The team of this advertising company was Read more about MongoDB Installation – Ubuntu[…]

Mongo DB – An Introduction
About NoSQL: Let’s understand about the NoSQL. We will explore MongoDB and it’s inception later. Like any other type of database NoSQL database also provides a mechanism to store and retrieve which is modeled in such a way so that it should be different than Relational database. In short, a NoSQL database does not store Read more about Mongo DB – An Introduction[…]
How to re-organize your data files of a tablespace
Problem statement: How to move data files from one location to another on same storage. How to move data files from one storage to another. How to rename data files to make data file name standardized Environment / Scenario: You have a database where you have to move your data files from old slower storage Read more about How to re-organize your data files of a tablespace[…]
How to copy Multi terabyte data to another Database Server
Problem statement: How to migrate huge data from One DB to another DB. Multi-Terabyte data loaded on one database should be copied to another database. Environment: You have multi-terabyte Database Your database is growing on daily basis, based on data feeds. Number of Indexes on these tables are very high, and thus, size of indexes Read more about How to copy Multi terabyte data to another Database Server[…]
Move DB with Oracle 11g Binaries
Problem Statement: Move DB with Oracle Binaries on New Storage Create new DEV/UAT from Production. Scenarios: While creating new UAT or DEV from production and make this version of oracle to the same patch set level as of production, there are more than to move DB with Oracle Binaries. Examples: One way to move DB Read more about Move DB with Oracle 11g Binaries[…]

How to: Speed up Inserts in database
We have written blogs which helps DBA doing their day to day works. This blog will explain how to Speed up Inserts while loading data from huge files. Problem Statement: The problem statement this blog is going to answers with respect to Speed up Inserts are: How to speed up loading millions of rows from Read more about How to: Speed up Inserts in database[…]
Reduce in MapReduce … Unwinding
In our previous blogs we have studied about Big data, Hadoop. We have also explained MapReduce internal workings like how Map works using short and shuffle. This blog is dedicated to Reduce in MapReduce. Once this shuffling completed, it is where Reduce in MapReduce come into action. Its task is to process the input provided Read more about Reduce in MapReduce … Unwinding[…]
MapReduce – Sort & Shuffle
This is in continuation of MapReduce Processing We are going to see how the input is provided to SORT process, how this is sorted and distributed on all available DNs and this input is taken over to the next step Shuffle. This output will be input for next process which is SORT. Sort takes Read more about MapReduce – Sort & Shuffle[…]

MapReduce – Unwinding Map
In last discussion on MapReduce, we discussed the algorithm which is used by Hadoop for data processing using MapReduce. In this blog, we will discuss the specific section of MAP in MapReduce and it’s functionality. Unwinding Map We will explain this in details and with example here. Example: Lets consider our scenario : The Scenario: Read more about MapReduce – Unwinding Map[…]
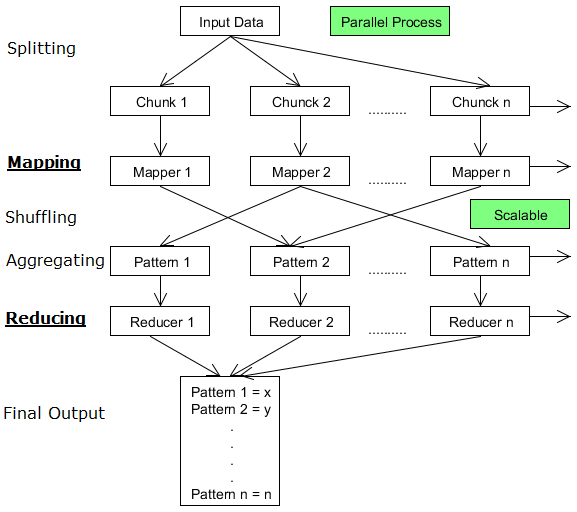
MapReduce – Unwinding Algorithm
With discussion, in my last blog, about “How Hadoop manages Fault Tolerance” within its cluster while processing data, it is now time to discuss the algorithm which MapReduce uses. Name Node (NN) It is Name Node (NN) where a user submits his request to process data and submits his data files. As soon as NN receives data Read more about MapReduce – Unwinding Algorithm[…]
MapReduce : Fault Tolerance
The Fault Tolerance: Before we see the intermediate data produced by the mapper, it would be quite interesting to see the fault tolerant aspects of Hadoop with respect to MapReduce processing. The Replication Factor: Once Name node (NN) received data files which has to be processed, it splits data files to assign it to Data Read more about MapReduce : Fault Tolerance[…]
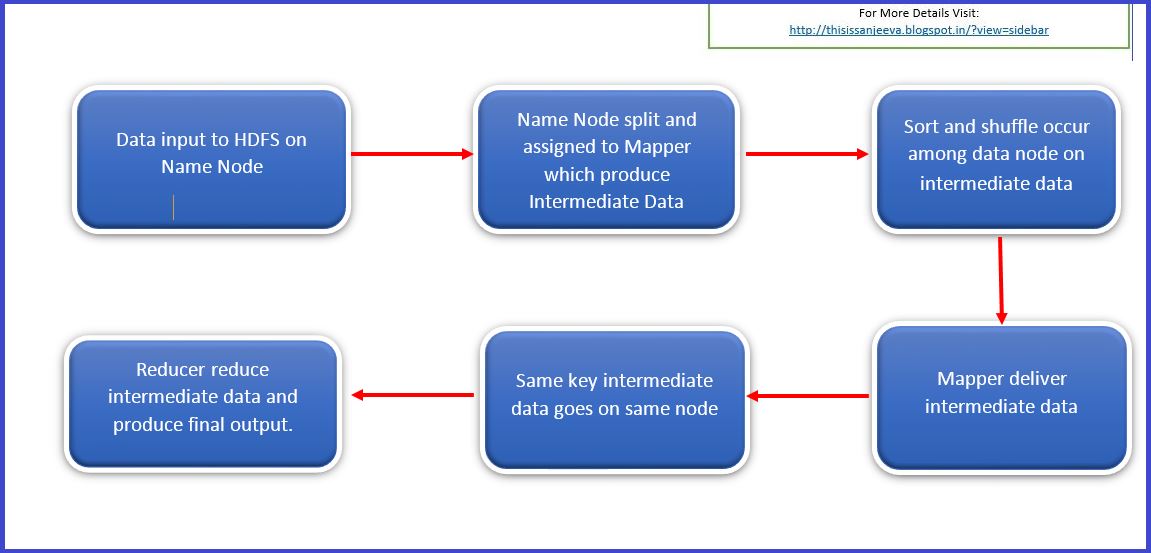
MapReduce Internals: Philosophy
In our last few blogs we have explained what is BigData, How Hadoop evolved & MapReduce workings. In this blog we will see the philosophy of MapReduce. The Philosophy: The philosophy of MapReduce internals workings is straight forward and can be summarized in 6 steps. The smaller, the better, the quicker: Whatever data we provide Read more about MapReduce Internals: Philosophy[…]
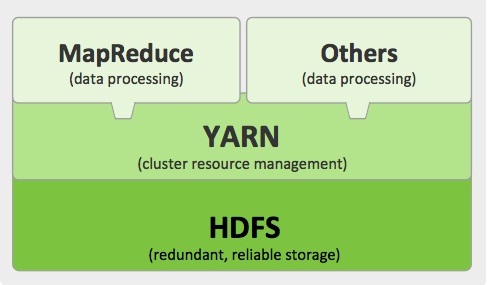
MapReduce : Internals
The MapReduce Framework: MapReduce is a programming paradigm that provides an interface for developers to map end-user requirements (any type of analysis on data) to code. This framework is one of the core components of Hadoop. The capabilities: The way it provides fault-tolerant and massive scalability across hundreds or thousands of servers in a cluster Read more about MapReduce : Internals[…]
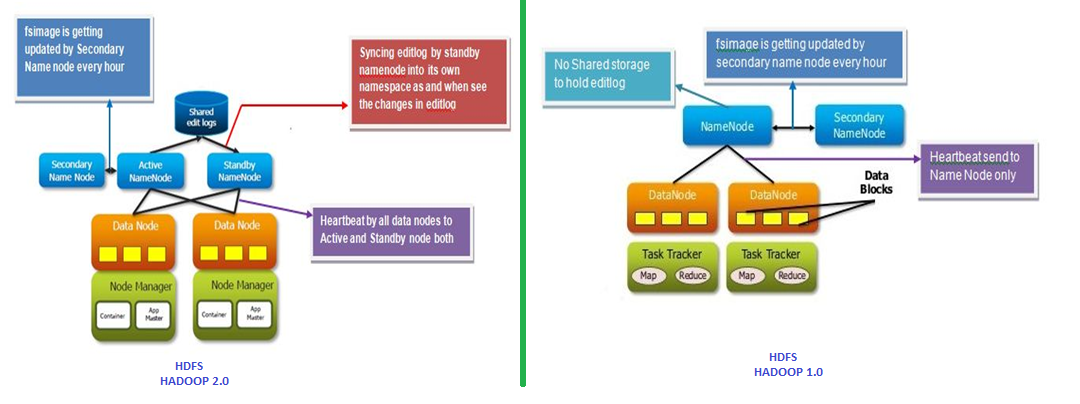
HDFS Architecture : Explained
Inspired by Google’s GFS,
HDFS (Hadoop Distributed File System ) architecture has designed in such a way that it has excellent fault-tolerant and self-healing features. It enables Hadoop to harness the true capability of distributed processing techniques…..

Magic of Hadoop
Disadvantage of DWH: Because of the limitation of currently available Enterprise data warehousing tools, Organizations were not able to consolidate their data at one place to maintain faster data processing. Here comes the magic of hadoop for their rescue. Traditional ETL tools may take hours, days and sometimes even weeks. And because of this, performances Read more about Magic of Hadoop[…]

Journey of Hadoop
History of Hadoop: At the outset of twenty-first century, somewhere 1999-2000, due to increasing popularity of XML and JAVA, internet was evolving faster than ever. This leads to the invention of Hadoop. Requirement is mother of invention: As the world wide web grew at dizzying pace, though current search engine technologies were working fine, a Read more about Journey of Hadoop[…]

Big Data: Introduction and 4V’s
Innovations in technologies made the resources cheaper than earlier. This enables organizations to store more data at lower cost and thus increasing the size of data. Gradually the size of data becomes bigger and now it moves from Megabytes (MB) to Petabytes (1e+9 MB). This huge increase in data requires some different kind of processing. Read more about Big Data: Introduction and 4V’s[…]