Index unique scan is the fastest access path Oracle’s optimizer can choose — it returns exactly one row using a single B-tree traversal, with zero ambiguity. If you see INDEX UNIQUE SCAN in an execution plan, that part of the query is already optimal. This post shows the execution plan on a primary key lookup, verified on Oracle 19c, and how it differs from index range scan.
Index unique scan is the optimizer access path where the database returns at most one row.
When the Oracle optimizer knows with certainty that a column carries a unique or primary key constraint, it treats the lookup differently from any other index scan. It reads the index structure in order for the specified key value and stops processing the moment it finds the first matching entry. There is no need to continue — no second record is possible by definition. The uniqueness guarantee is enforced at the constraint level, and the optimizer is smart enough to exploit that guarantee at execution time.
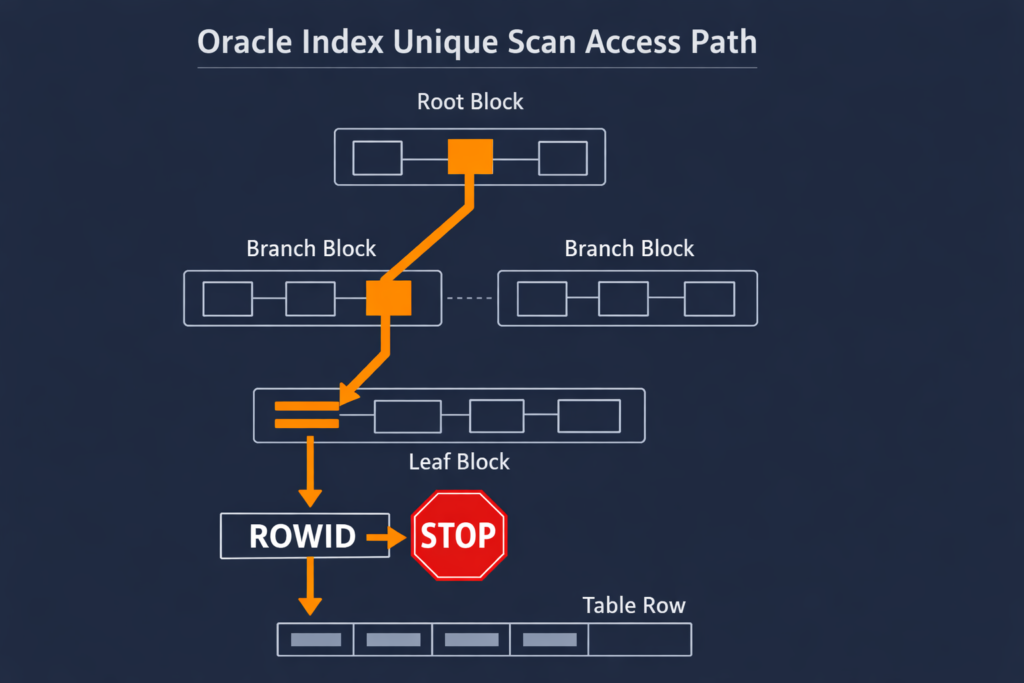
The mechanics are straightforward but worth understanding clearly. The optimizer traverses the B-tree index from the root block down through the branch blocks until it reaches the leaf block containing the target key. At that leaf block, it picks up the rowid — the physical address of the row in the data segment. It then performs a single I/O to retrieve that exact row from the table. The scan stops immediately after. No additional leaf blocks are visited, no extra table I/Os are triggered.
-- Setup
CREATE TABLE emp (
empno NUMBER PRIMARY KEY,
ename VARCHAR2(20),
deptno NUMBER
);
-- Query with equality predicate on primary key
EXPLAIN PLAN FOR
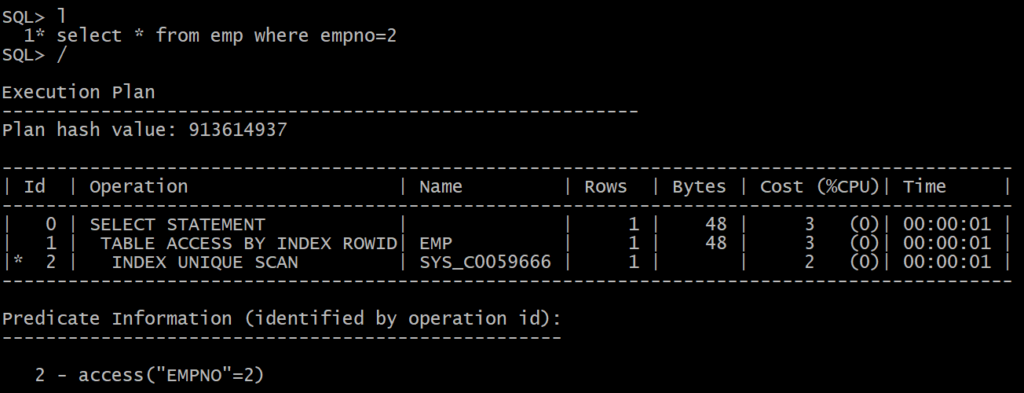
SELECT ename, deptno FROM emp WHERE empno = 7839;
SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY);---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 13 | 1 |
| 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 13 | 1 |
|* 2 | INDEX UNIQUE SCAN | EMP_PK | 1 | | 0 |
---------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("EMPNO"=7839)This is what makes index unique scan the gold standard among index access paths. It is precise, deterministic, and carries the lowest possible overhead for a row lookup. In production systems handling millions of transactions per day, this distinction matters enormously. Every other index access path — range scan, full scan, fast full scan — has some degree of uncertainty or breadth built into it. Index unique scan has none.
The optimizer chooses this path only when two conditions are met: the query predicate uses an equality condition on the indexed column, and that column is backed by a unique index or a primary key constraint. If either condition is absent, the optimizer falls back to an index range scan instead.
In our example, we have created a primary key on the column empno, which in turn creates a unique index on this column. When a query filters on empno with an equality predicate, the optimizer recognizes the uniqueness constraint and selects index unique scan automatically — no hints, no manual intervention required. This is the optimizer working exactly as designed.

Worth Reading content:
2 thoughts on “Optimizer Access Paths: index unique scan”