Last Updated: June 2026
Tested On: Oracle 19c
Your AWR shows INDEX FAST FULL SCAN on a query that runs every 5 minutes. The index exists. The query looks fine. But something feels off — why is Oracle reading the entire index instead of doing a range scan?
Sound familiar?
This post explains exactly what Oracle index fast full scan is, when the optimizer picks it, how it differs from index full scan, and two real scenarios where understanding FFS changed the execution plan — including the DISTINCT trap that catches most DBAs off guard.
What Is Index Fast Full Scan?
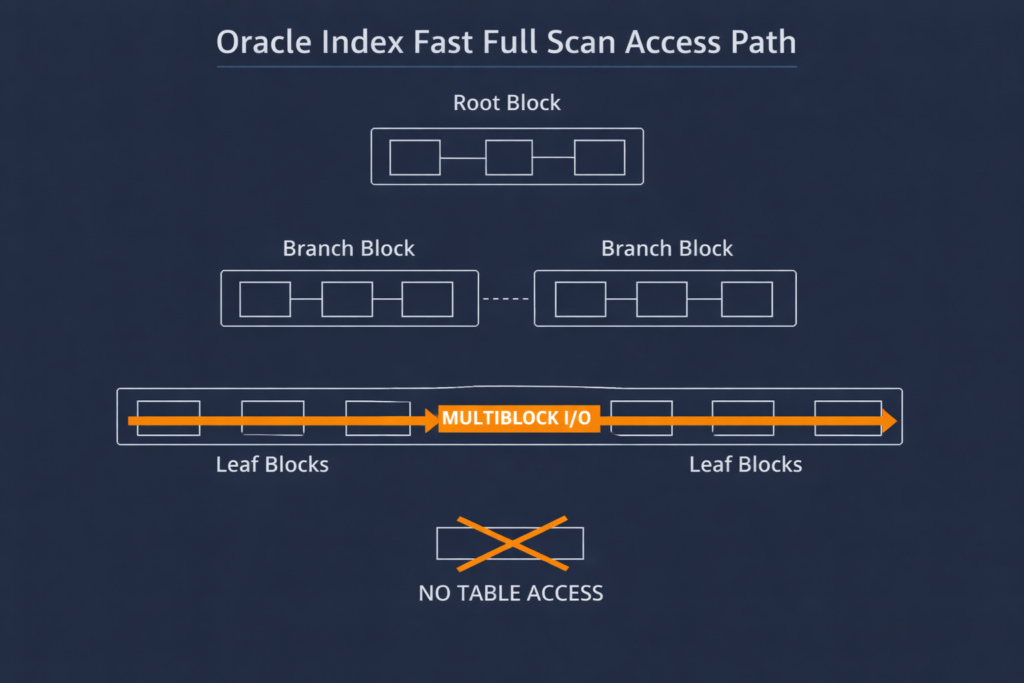
Index fast full scan reads the entire index as it exists on disk — unsorted, using multiblock I/O.
Unlike index full scan which traverses the B-tree leaf chain from left to right one block at a time, fast full scan ignores the tree structure entirely. It reads all leaf blocks, branch blocks, and root blocks in physical disk order, processes only the leaf block data, and discards the rest.
The optimizer treats the index as a skinny version of the table — all the columns it needs are in the index, so it never touches the table itself.
Key characteristics:
- Multiblock I/O — reads multiple blocks per I/O call, same mechanism as full table scan
- Unsorted output — data comes back in physical disk order, not index key order
- No table access — index must contain every column the query needs
- Parallel capable — can use parallel query, unlike index full scan
When Does the Optimizer Choose Index Fast Full Scan?
Two conditions must both be true:
1. All columns needed by the query exist in the index
The optimizer never touches the table. If the SELECT, WHERE, or GROUP BY references a column not in the index, FFS is not possible.
2. Sorted output is not required
Because multiblock I/O reads in physical disk order, the output is unsorted. If the query has an ORDER BY on the indexed columns, the optimizer will prefer index full scan instead — which delivers sorted output via single block I/O leaf chain traversal.
Scenario 1: COUNT with GROUP BY
sql
-- Query
SELECT count(job) FROM emp;
-- Index
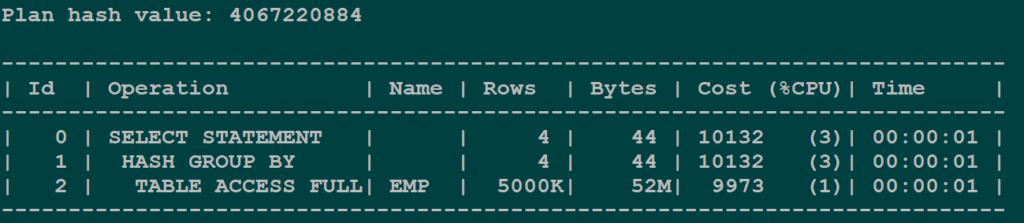
CREATE INDEX idx_emp_job ON emp(job);Pre-index plan: Full table scan — optimizer reads every row in the table.
The explain plan is itself explanatory.
Pre-Index Plan
Post-index plan: INDEX FAST FULL SCAN on idx_emp_job — optimizer recognises that count(job) can be answered entirely from the index. No table access. The index is the skinny table.
Post-Index Plan
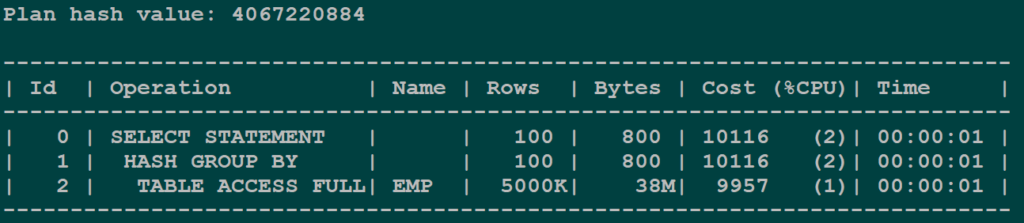
This is the cleanest FFS scenario. The query needs one indexed column, no sort order, COUNT aggregation. Multiblock I/O on the index is cheaper than a full table scan.
Scenario 2: The DISTINCT Trap
sql
-- Query
SELECT DISTINCT job FROM emp;
-- Index
CREATE INDEX idx_emp_job ON emp(job);Pre-index plan: Full table scan.
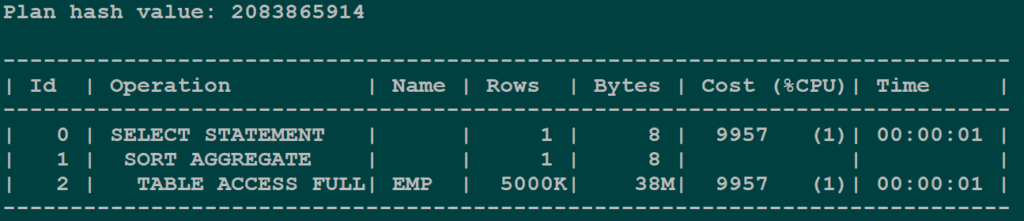
Pre-Index PlanPost-index plan: Still full table scan. The index exists — why isn’t the optimizer using it?

Post-Index PlanThe reason: When Oracle builds a B-tree index, it excludes NULL values. The optimizer cannot guarantee from the index alone that there are no NULL values in the job column. To safely return DISTINCT results, it must check the table — which forces a full table scan.
The fix:
sql
ALTER TABLE emp MODIFY job NOT NULL;After this, the optimizer knows the column contains no NULLs. It can now satisfy DISTINCT job entirely from the index — and switches to INDEX FAST FULL SCAN.
This is the single most common reason DBAs see a full table scan on a query with a perfectly valid index on the SELECT column. The column allows NULLs. The optimizer has no choice.
Index Fast Full Scan vs Index Full Scan
Both scan the entire index. The mechanism is completely different.
| Aspect | Index Fast Full Scan | Index Full Scan |
|---|---|---|
| I/O Type | Multiblock I/O | Single block I/O |
| Read Order | Physical disk order | Leaf chain (left to right) |
| Output Sorted? | No | Yes — index key order |
| Avoids Sort? | No | Yes |
| Parallelism | Yes | No |
| Use Case | All rows needed, order doesn’t matter | Sorted results from index, no sort operation wanted |
The optimizer’s decision logic: If sorted output is required and all columns are in the index — index full scan. If sort order doesn’t matter and bulk throughput is the goal — index fast full scan, because multiblock I/O is faster for high-volume reads.
When Index Fast Full Scan Becomes a Problem
FFS is efficient when the index is significantly smaller than the table. It becomes a problem when:
- The index is large — multiblock I/O on a massive index still generates significant I/O
- The query runs at high frequency — every execution re-reads the entire index
- Buffer cache cannot hold the index — physical reads dominate
Check db file scattered read waits in AWR when FFS is suspected. Scattered reads are the wait event signature of multiblock I/O — they appear on both full table scans and index fast full scans.
sql
-- Check index size to evaluate FFS cost
SELECT index_name, leaf_blocks, num_rows, last_analyzed
FROM user_indexes
WHERE index_name = 'IDX_EMP_JOB';If leaf_blocks is large and the query runs frequently, consider whether a covering index with fewer columns, or a different query approach, reduces the FFS footprint.
Key Takeaways
Index fast full scan reads the entire index using multiblock I/O in physical disk order — unsorted, no table access, parallel-capable. The optimizer picks it when all query columns are in the index and sorted output is not required.
The DISTINCT trap is the most common production surprise: a valid index on the SELECT column doesn’t get used because the column allows NULLs. ALTER TABLE ... MODIFY col NOT NULL is the fix — after which the optimizer switches from full table scan to index fast full scan.
When you see FFS in an AWR report, check db file scattered read waits and index size before tuning. FFS is often the correct path — but on large indexes with high-frequency queries, it deserves a second look.
Related posts in this series:
2 thoughts on “Oracle Index Fast Full Scan: When the Optimizer Reads the Entire Index”