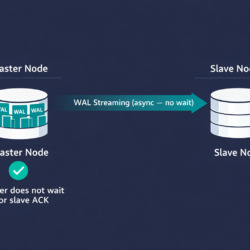
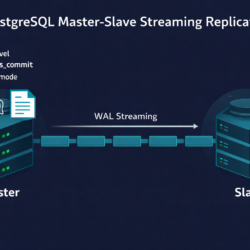
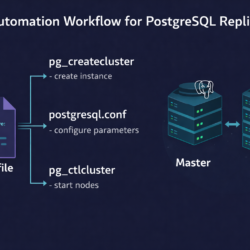
Cannot Drop Columns from View in PostgreSQL — Fix [42P16]
You added a column to a PostgreSQL view. Now you want it gone. You ran CREATE OR REPLACE VIEW with fewer columns and PostgreSQL stopped you cold: Your table is fine. Your data is safe. But CREATE OR REPLACE VIEW has one hard rule — it can add columns at the end, but it cannot Read more about Cannot Drop Columns from View in PostgreSQL — Fix [42P16][…]