We have explored the PostgreSQL implementation of MVCC in the last two blogs. We will understand the pros and cons of this way of implementation in this blog.
PostgreSQL MVCC Pros and Cons in Production
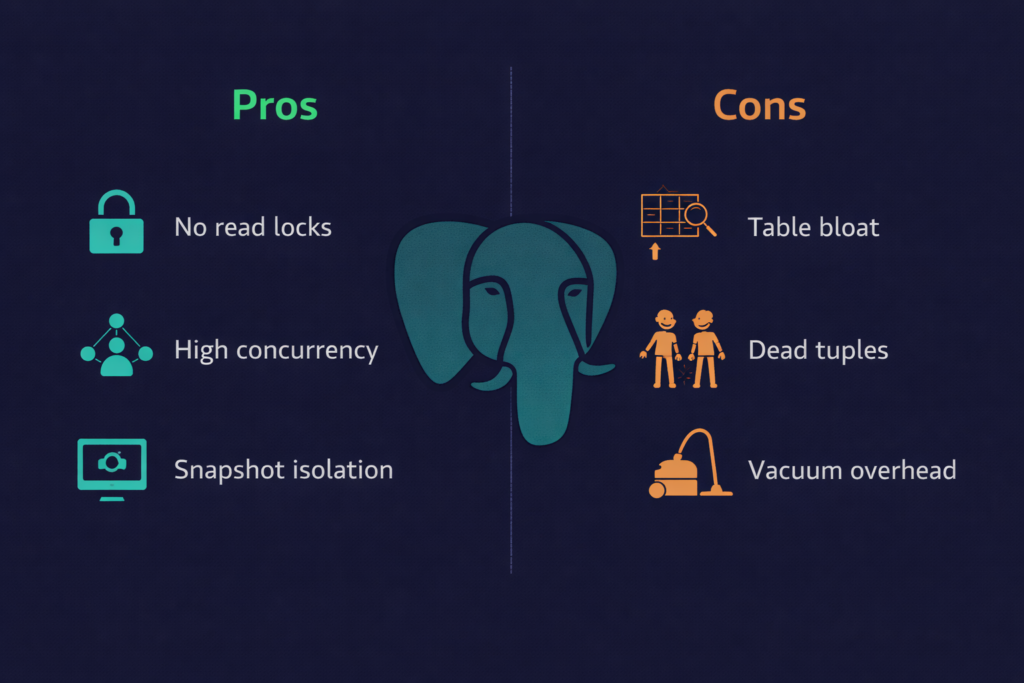
Understanding the PostgreSQL MVCC pros and cons helps DBAs make informed decisions about vacuum tuning, table design, and when bloat becomes a real performance concern.
This implementation avoided the need for locking of a tuple for any possible updates because the updates are not in-place. Updates in PostgreSQL are creating a complete new tuple which will be a copy of the existing tuple with updated values including keeping the existing tuple intact. However, this means that for one tuple which went multiple updates, the database will have multiple copies of that tuple. The visibility of these tuples to the transaction is based on the XID i.e. xmin & xmax. Also in case of deletion, no tuple was actually deleted by the database. They are just marked as deleted using the same method of xmin & xmax (XID).
The old tuples which will not be visible to the transactions are termed as dead tuples. This creates many issues like bloating into indexes and tables, multi-fold storage requirements, and transaction ID wraparound or multixact ID wraparound. Let’s understand this one by one.
Because of huge number of transactions, there will be many dead records which will not be visible to the transactions. This means, lot of blocks of a table will hold the dead rows and thus index also has the same dead rows. These are known as bloating issues in tables/indexes which needs to be fixed in routine manner.
Since, these dead rows are exact copy of the tuples, they took the same amount of spaces on disk. If indexes exists on such table, it also took the spaces. For example, if a record has updated 7 times after its creation, there will be 8 record exists on the disk and thus it will use 8 times storage.
The issue of transaction ID wraparound is quite interesting. This issue is because of two things, the one is the MVCC way of implementation and the other is because the transaction ID (XID) is limited to 32 bits only and this means you have only 4 billion transactions available. Beyond that, it will restart to the beginning and this is where all your existing transactions will not be visible as their xmin would be far more than the current XID. In short, catastrophic data loss will occur.
PostgreSQL has provided a solution to these problems. The VACUUM process will fix these issues. We will explore the details of the VACUUM process in another blog. That is why the database asks for a must VACUUM for every table of the database at least once every two billion transactions. To make this easier for maintenance, the database has come-up with the autovacuum process which a vacuuming task automatically for any table which is required across the database.
Series of blogs on MVCC :
2 thoughts on “MVCC Concurrency Architecture: PostgreSQL way of implementation – III( pros/cons)”