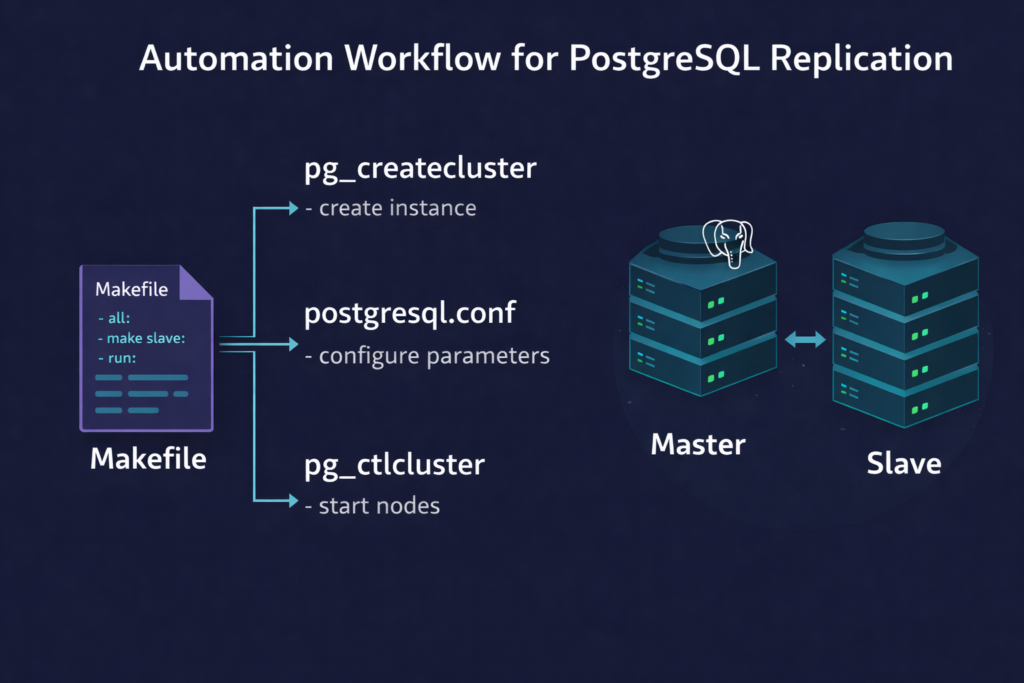
Master-slave replication setup is the implementation of HA in PostgreSQL. Deployment architecture of 1 master and at least one slave in SYNC mode would be able to provide senses of High Availability of the database.
To achieve this we require some steps to be performed into the database which will make one of the nodes as master and one of the nodes as slave. We will discuss the details of these steps in another blog, however in this blog, we will restrict ourselves just to automate the entire steps so that we can perform these steps without human interventions.
For the blogging purpose, I will use one VM to do this, however, we can achieve the same with as many VMs in our HA cluster.
There are more than one ways to achieve this like a shell script, a python script, or even a makefile. In this blog, we will explore how a makefile makes our life easy.
Let me explain what a makefile does in a Unix environment. A makefile is the input source for the Unix make command. This command is used to determine automatically which pieces of a large program need to be recompiled, and issue the commands to recompile them.
Let’s explore the structure of makefile and how the make command uses this file. A typical makefile structure should like like:

Structure of makefileThe word “pgstartdb” is the first line and it is the command which make will use to figure out what all instructions it needs to execute. This word will end with a semicolon (:). All subsequent lines till the end or until the next command will start with a tab as stated in the image.
To automate the entire task we new few PostgreSQL utilities which will be listed here. We will talk in details about these utilities in another blog.
- pg_createcluster : This will create a new instance of database
- pg_ctlcluster: This will manage all instances of database. We are use to start and shutdown only in this automation blog.
- pg_lsclusters: This will list all instances of database.
We also require few configuration to be updated to new values which are be listed here. We will talk in details about these utilities in another blog. The values of these parameters depends on the VM’s configuration to the some extent.
- max_wal_size
- wal_keep_segments
- min_wal_size
- max_wal_senders
- wal_keep_segments
- max_replication_slots
- listen_addresses
- synchronous_commit
- synchronous_standby_names
- hot_standby
- archive_mode
- archive_command
These configurations are to be updated in postgresql.conf which we really don’t want to touch, hence, we have created another new conf file with name “pgrepl.conf” and this will be copied hooked automatically at the location of postgresql.conf with out automation script.
The Replication series blogs are:
- Data Replication Setup Using Master and Slave: PostgreSQL – I
- Data Replication Setup Using Master and Slave: PostgreSQL – II
- Data Replication Setup Using Master and Slave: PostgreSQL- III
- Data Replication Setup Using Master and Slave: PostgreSQL- IV
- PostgreSQL Meta-Command using psql: Command Information -IV