Reduce in MapReduce … Unwinding
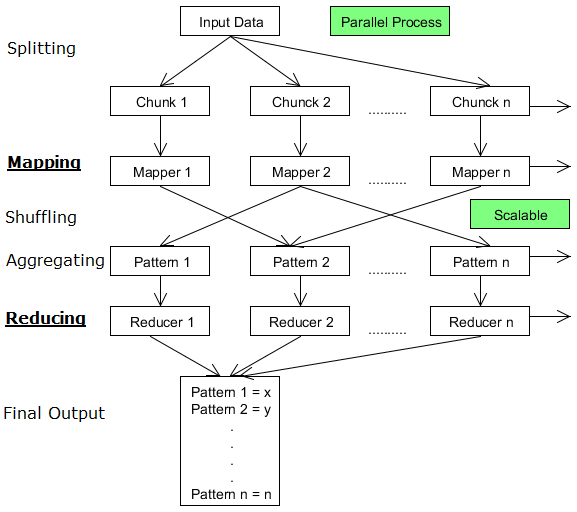
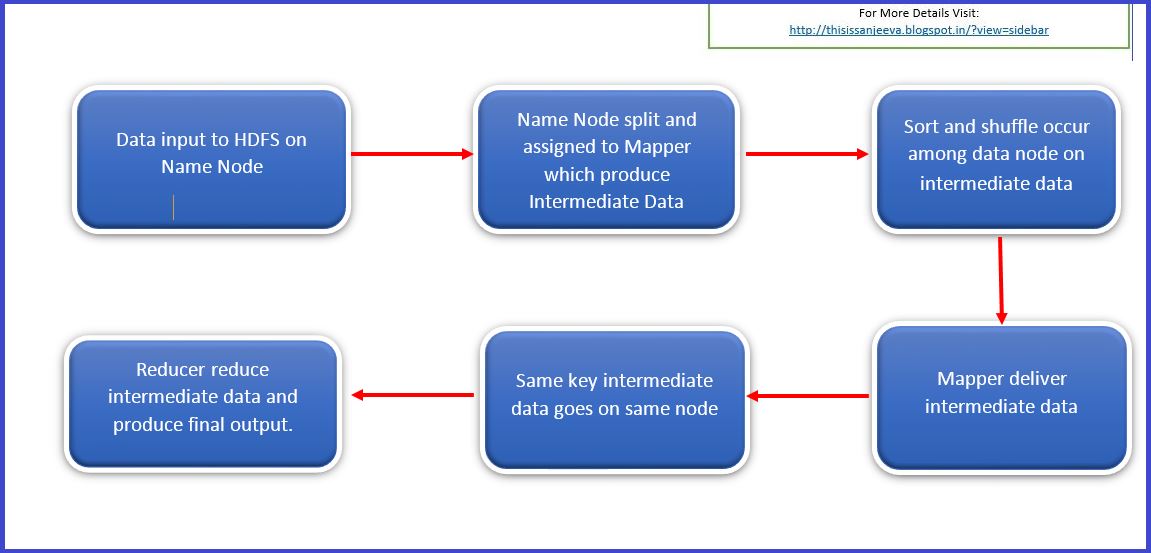
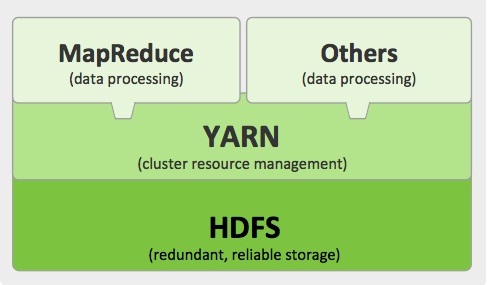
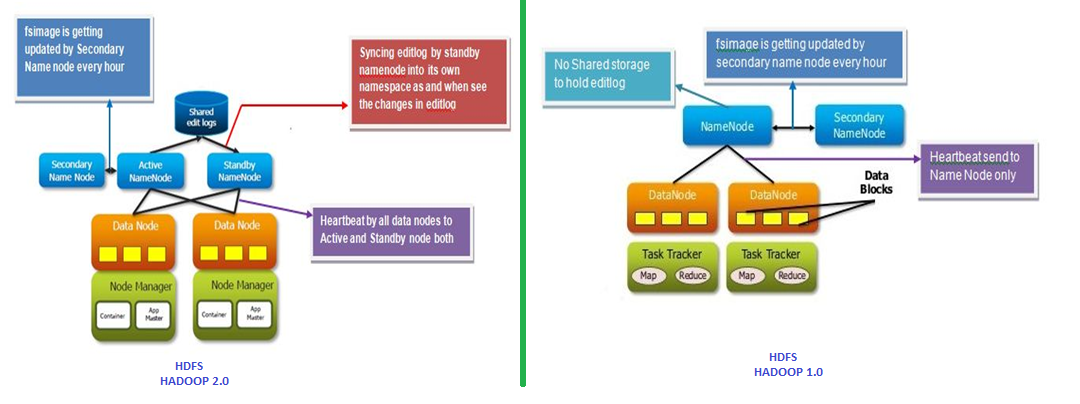
In our previous blogs we have studied about Big data, Hadoop. We have also explained MapReduce internal workings like how Map works using short and shuffle. This blog is dedicated to Reduce in MapReduce. Once this shuffling completed, it is where Reduce in MapReduce come into action. Its task is to process the input provided Read more about Reduce in MapReduce … Unwinding[…]