With discussion, in my last blog, about “How Hadoop manages Fault Tolerance” within its cluster while processing data, it is now time to discuss the algorithm which MapReduce uses.
Name Node (NN)
It is Name Node (NN) where a user submits his request to process data and submits his data files.
As soon as NN receives data files, it splits the data files into smaller chunks and distribute it to the Data Node (DN) for further processing.
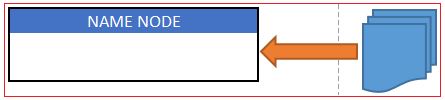
NN splits this data file into packets (K) and assigns these packets to DN.

Map
As soon as DN takes data packets, Map comes into play.
It splits this in to list of K i.e. [L <K>] and add values to it. Hence, it becomes “List of Key-Value pair” [L<K,V>].
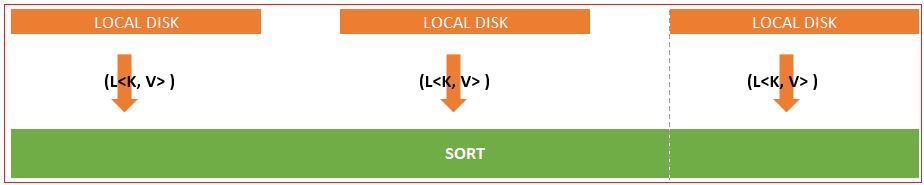
Once this is done this output would be written to local disk of DN.

Data Nodes
Next steps will kicked off only when all DN finished its task. If any DN has not finished its work then all other DN will wait for it to complete its task.
Between Map and Reduce, there are two intermediate processes which are known as SORT and SHUFFLE.
SORT
Once all DN completes its processing and Map’s output is written to disk, Sort starts working and does a sorting on the output.
This process runs on each DN. The output is again “List of Key-Value Pair” L<K,V>, but this time in sorted order on each node.
Shuffle
Shuffle works on sorted output.
It takes each L<K,V> and negotiate among DN about which DN will process which L<K,V>. As and when it is finalized by DN for a L<K,V>, that particular L<K,V> is assigned to the same DN.
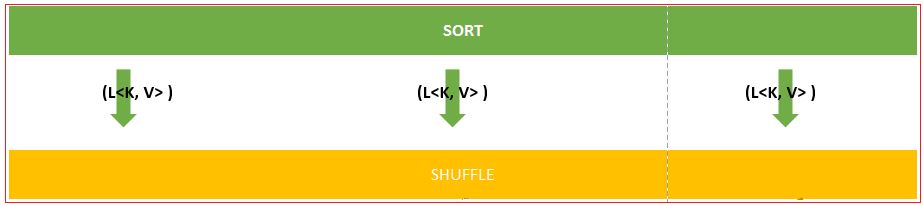
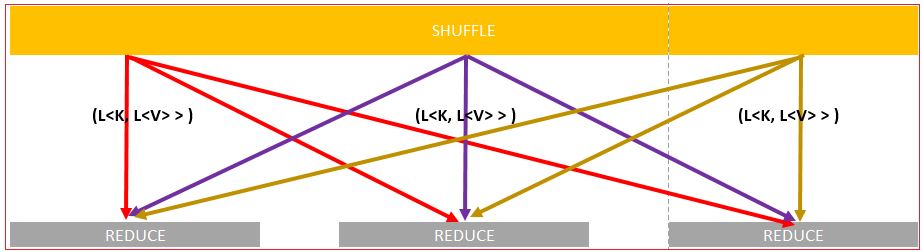
During process of shuffling this be ensured that none of DN will process same type of K. This means, one type of K will be processed by only one DN. Output of Shuffle is [L<K, L<V> >]
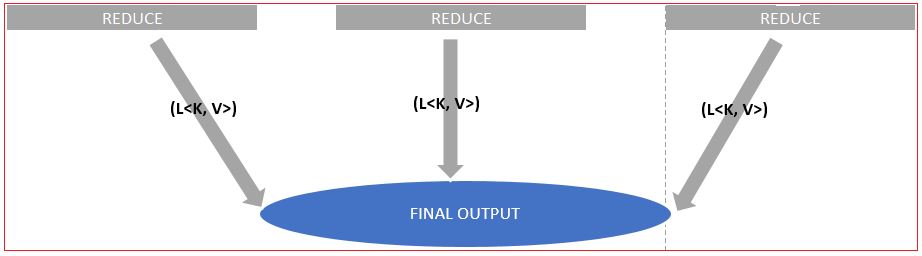
Reduce
This output [L<K, L<V> >] acts as input to Reduce process.
Reduce then, as per its name, reduces the list supplied to it as input and convert it into again “List of Key-Value Pair” [L<K,V >].
This time it will be final output of entire algorithm.
Next will be explanation of this algorithm with an example, coming soon……
1 thought on “MapReduce – Unwinding Algorithm”