We are going to see how the input is provided to SORT process, how this is sorted and distributed on all available DNs and this input is taken over to the next step Shuffle.
SORT
|
NODE – 1 [ L (K, V)] |
||||
|
PKT-1(K) |
V |
PKT-6(K) |
V |
|
|
With |
1 |
much |
1 |
|
|
the |
1 |
performance |
1 |
|
|
use |
1 |
. |
1 |
|
|
of |
1 |
hit |
1 |
|
|
parallel |
1 |
By |
1 |
|
|
processing |
1 |
harnessing |
1 |
|
|
design |
1 |
the |
1 |
|
|
Hadoop |
1 |
true |
1 |
|
|
overcome |
1 |
capability |
1 |
|
|
distributed |
1 |
of |
1 |
|
|
distributed |
1 |
|||
|
parallel |
1 |
|||
|
NODE – 3 [ L (K, V)] |
||||
|
PKT-4(K) |
V |
PKT-9(K) |
V |
|
|
, |
1 |
get |
1 |
|
|
, |
1 |
Hadoop |
1 |
|
|
achieved |
1 |
huge |
1 |
|
|
adding |
1 |
its |
1 |
|
|
an |
1 |
limitations |
1 |
|
|
analysis |
1 |
machines |
1 |
|
|
any |
1 |
minute |
1 |
|
|
best |
1 |
new |
1 |
|
|
by |
1 |
of |
1 |
|
|
By |
1 |
organization |
1 |
|
|
can |
1 |
part |
1 |
|
|
commodity |
1 |
the |
1 |
|
|
data |
1 |
this |
1 |
|
|
enabling |
1 |
with |
1 |
|
|
within |
1 |
|||
|
without |
1 |
|||
|
1 |
||||
|
for |
1 |
|||
|
NODE – 4 [ L (K, V)] |
||||
|
PKT-3(K) |
V |
PKT-8(K) |
V |
|
|
. |
1 |
level |
1 |
|
|
also |
1 |
low |
1 |
|
|
be |
1 |
maximum |
1 |
|
|
but |
1 |
of |
1 |
|
|
can |
1 |
on |
1 |
|
|
data |
1 |
on |
1 |
|
|
decentralized |
1 |
processing |
1 |
|
|
granular |
1 |
relies |
1 |
|
|
hardware |
1 |
scaling |
1 |
|
|
horizontal |
1 |
scaling |
1 |
|
|
Horizontal |
1 |
speeds |
1 |
|
|
its |
1 |
technique |
1 |
|
|
the |
1 |
|||
|
to |
1 |
|||
|
up |
1 |
|||
|
NODE – 5 [ L (K, V)] |
||||
|
PKT-2(K) |
V |
PKT-7(K) |
V |
|
|
. |
1 |
enables |
1 |
|
|
. |
1 |
every |
1 |
|
|
allow |
1 |
Hadoop |
1 |
|
|
and |
1 |
its |
1 |
|
|
at |
1 |
low |
1 |
|
|
be |
1 |
machines |
1 |
|
|
can |
1 |
not |
1 |
|
|
capture |
1 |
only |
1 |
|
|
commodity |
1 |
organization |
1 |
|
|
configured |
1 |
processing |
1 |
|
|
cost |
1 |
scenarios |
1 |
|
|
data |
1 |
them |
1 |
|
|
data |
1 |
these |
1 |
|
|
decentralize |
1 |
This |
1 |
|
|
This |
1 |
|||
|
to |
1 |
|||
|
to |
1 |
|||
|
using |
1 |
|||
|
NODE – 6 [ L (K, V)] |
||||
|
PKT-5(K) |
V |
PKT-10(K) |
V |
|
|
accommodate |
1 |
data |
1 |
|
|
and |
1 |
ETL |
1 |
|
|
can |
1 |
for |
1 |
|
|
failure |
1 |
hours |
1 |
|
|
falut |
1 |
in |
1 |
|
|
hardware |
1 |
it |
1 |
|
|
is |
1 |
less |
1 |
|
|
machine |
1 |
tradition |
1 |
|
|
more |
1 |
very |
1 |
|
|
of |
1 |
waiting |
1 |
|
|
one |
1 |
was |
1 |
|
|
or |
1 |
which |
1 |
|
|
tolerent |
1 |
with |
1 |
|
|
type |
1 |
1 |
||
|
without |
1 |
1 |
||
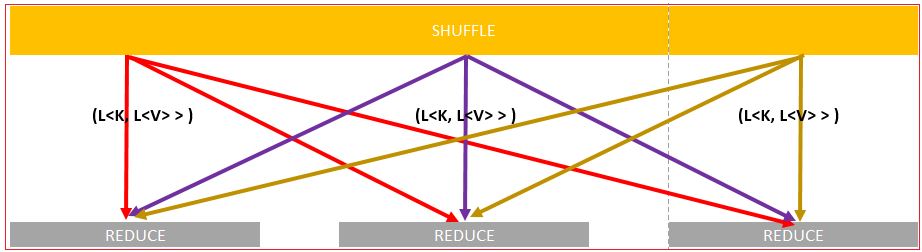
Once SORT completes it task of sorting on MAP output, next process SHUFFLE takes the charge.
SHUFFLE negotiates among DN and finds which DN is actually processing (counting in our scenario) which words.
Once this negotiation is done on all the nodes, shuffling of words starts among DNs. The scenario for shuffling in our case are:
|
DNs |
Word Start from |
|
DN-1 |
a-f |
|
DN-2 |
Node |
|
DN-3 |
g-l |
|
DN-4 |
m-p . , “” |
|
DN-5 |
q-t |
|
DN-6 |
u-z |
Colors are to denote and clarify the shuffling processing.
Lets see the shuffling on all DNs.
DN-1 says that it will process all words start with a to f, Hence all other nodes who contains words starts with letter a to f will assign back to DN-1. DN -1, in return, will assign all other node back their respective words.
This exchange process is known as shuffling.
The same happens at each DN i.e. DN -1 to DN -6. To make a better understanding we have used different colors for each DN so that representation should bring clear picture.
We have braked the process in understandable manner and represented in form of images which are indicating the way entire process progresses.
Let see one by one how shuffling takes place at each node for all other nodes.
Initially we are marking the word in DN’s color (as mentioned in above picture) which are going to pass to another DN in order to show the more clear picture of this process.
Shuffle
The output would be [L<K,V>]
|
NODE – 1 [ L (K, V)] |
|||
|
PKT-1(K) |
V |
PKT-6(K) |
V |
|
. |
1 |
of |
1 |
|
By |
1 |
of |
1 |
|
capability |
1 |
overcome |
1 |
|
design |
1 |
parallel |
1 |
|
distributed |
1 |
parallel |
1 |
|
distributed |
1 |
performance |
1 |
|
Hadoop |
1 |
processing |
1 |
|
harnessing |
1 |
the |
1 |
|
hit |
1 |
the |
1 |
|
much |
1 |
true |
1 |
|
use |
1 |
||
|
With |
1 |
||
|
NODE – 2 [ L (K, V)] |
|||
|
NODE – 3 [ L (K, V)] |
|||
|
PKT-4(K) |
V |
PKT-9(K) |
V |
|
, |
1 |
get |
1 |
|
, |
1 |
Hadoop |
1 |
|
achieved |
1 |
huge |
1 |
|
adding |
1 |
its |
1 |
|
an |
1 |
limitations |
1 |
|
analysis |
1 |
machines |
1 |
|
any |
1 |
minute |
1 |
|
best |
1 |
new |
1 |
|
by |
1 |
of |
1 |
|
By |
1 |
organization |
1 |
|
can |
1 |
part |
1 |
|
commodity |
1 |
the |
1 |
|
data |
1 |
this |
1 |
|
enabling |
1 |
with |
1 |
|
for |
1 |
within |
1 |
|
without |
1 |
||
|
1 |
|||
|
NODE – 4 [ L (K, V)] |
|||
|
PKT-3(K) |
V |
PKT-8(K) |
V |
|
. |
1 |
level |
1 |
|
also |
1 |
low |
1 |
|
be |
1 |
maximum |
1 |
|
but |
1 |
of |
1 |
|
can |
1 |
on |
1 |
|
data |
1 |
on |
1 |
|
decentralized |
1 |
processing |
1 |
|
granular |
1 |
relies |
1 |
|
hardware |
1 |
scaling |
1 |
|
horizontal |
1 |
scaling |
1 |
|
Horizontal |
1 |
speeds |
1 |
|
its |
1 |
technique |
1 |
|
the |
1 |
||
|
to |
1 |
||
|
up |
1 |
||
|
NODE – 5 [ L (K, V)] |
|||
|
PKT-2(K) |
V |
PKT-7(K) |
V |
|
. |
1 |
enables |
1 |
|
. |
1 |
every |
1 |
|
allow |
1 |
Hadoop |
1 |
|
and |
1 |
its |
1 |
|
at |
1 |
low |
1 |
|
be |
1 |
machines |
1 |
|
can |
1 |
not |
1 |
|
capture |
1 |
only |
1 |
|
commodity |
1 |
organization |
1 |
|
configured |
1 |
processing |
1 |
|
cost |
1 |
scenarios |
1 |
|
data |
1 |
them |
1 |
|
data |
1 |
these |
1 |
|
decentralize |
1 |
This |
1 |
|
This |
1 |
||
|
to |
1 |
||
|
to |
1 |
||
|
using |
1 |
||
|
NODE – 6 [ L (K, V)] |
|||
|
PKT-5(K) |
V |
PKT-10(K) |
V |
|
accommodate |
1 |
more |
1 |
|
and |
1 |
of |
1 |
|
can |
1 |
one |
1 |
|
data |
1 |
or |
1 |
|
ETL |
1 |
tolerent |
1 |
|
failure |
1 |
tradition |
1 |
|
falut |
1 |
type |
1 |
|
for |
1 |
very |
1 |
|
hardware |
1 |
waiting |
1 |
|
hours |
1 |
was |
1 |
|
in |
1 |
which |
1 |
|
is |
1 |
with |
1 |
|
it |
1 |
without |
1 |
|
less |
1 |
1 |
|
|
machine |
1 |
1 |
|
|
NODE – 1 [ L (K, V)] |
||||
|
(K) |
V |
|
(K) |
V |
|
achieved |
1 |
|
accommodate |
1 |
|
adding |
1 |
|
also |
1 |
|
allow |
1 |
|
an |
1 |
|
and |
1 |
|
analysis |
1 |
|
any |
1 |
|
and |
1 |
|
at |
1 |
|
be |
1 |
|
be |
1 |
|
but |
1 |
|
best |
1 |
|
By |
1 |
|
by |
1 |
|
can |
1 |
|
By |
1 |
|
can |
1 |
|
can |
1 |
|
can |
1 |
|
capability |
1 |
|
commodity |
1 |
|
capture |
1 |
|
configured |
1 |
|
commodity |
1 |
|
cost |
1 |
|
data |
1 |
|
data |
1 |
|
data |
1 |
|
data |
1 |
|
decentralize |
1 |
|
data |
1 |
|
design |
1 |
|
decentralized |
1 |
|
distributed |
1 |
|
enabling |
1 |
|
distributed |
1 |
|
failure |
1 |
|
enables |
1 |
|
falut |
1 |
|
ETL |
1 |
|
for |
1 |
|
every |
1 |
|
for |
1 |
|
NODE – 2 [ L (K, V)] |
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
NODE – 3 [ L (K, V)] |
||||
|
(K) |
V |
|
(K) |
V |
|
get |
1 |
|
granular |
1 |
|
Hadoop |
1 |
|
hardware |
1 |
|
Hadoop |
1 |
|
horizontal |
1 |
|
Hadoop |
1 |
|
Horizontal |
1 |
|
hardware |
1 |
|
hours |
1 |
|
harnessing |
1 |
|
in |
1 |
|
hit |
1 |
|
it |
1 |
|
huge |
1 |
|
its |
1 |
|
is |
1 |
|
less |
1 |
|
its |
1 |
|
level |
1 |
|
its |
1 |
|
low |
1 |
|
limitations |
1 |
|
|
|
|
low |
1 |
|
|
|
|
NODE – 4 [ L (K, V)] |
||||
|
(K) |
V |
|
(K) |
V |
|
, |
1 |
|
, |
1 |
|
. |
1 |
|
. |
1 |
|
. |
1 |
|
machine |
1 |
|
. |
1 |
|
machines |
1 |
|
machines |
1 |
|
maximum |
1 |
|
minute |
1 |
|
more |
1 |
|
much |
1 |
|
new |
1 |
|
of |
1 |
|
not |
1 |
|
of |
1 |
|
on |
1 |
|
of |
1 |
|
only |
1 |
|
of |
1 |
|
or |
1 |
|
of |
1 |
|
organization |
1 |
|
on |
1 |
|
overcome |
1 |
|
one |
1 |
|
parallel |
1 |
|
organization |
1 |
|
parallel |
1 |
|
part |
1 |
|
performance |
1 |
|
|
1 |
|
processing |
1 |
|
|
1 |
|
processing |
1 |
|
|
1 |
|
processing |
1 |
|
NODE – 5 [ L (K, V)] |
||||
|
(K) |
V |
|
(K) |
V |
|
speeds |
1 |
|
relies |
1 |
|
the |
1 |
|
scaling |
1 |
|
the |
1 |
|
scaling |
1 |
|
the |
1 |
|
scenarios |
1 |
|
the |
1 |
|
technique |
1 |
|
them |
1 |
|
these |
1 |
|
this |
1 |
|
This |
1 |
|
This |
1 |
|
to |
1 |
|
to |
1 |
|
tolerent |
1 |
|
to |
1 |
|
tradition |
1 |
|
true |
1 |
|
type |
1 |
|
NODE – 6 [ L (K, V)] |
||||
|
(K) |
V |
|
(K) |
V |
|
up |
1 |
|
using |
1 |
|
use |
1 |
|
very |
1 |
|
With |
1 |
|
waiting |
1 |
|
with |
1 |
|
was |
1 |
|
within |
1 |
|
which |
1 |
|
without |
1 |
|
with |
1 |
|
without |
1 |
|
|
|
With this, we have all the DNs the words which they are going to process for our word count program.
Coming up next ……… Reduce
1 thought on “MapReduce – Sort & Shuffle”