The Inspiration:
GFS is developed using C++ in 2003 by Google to enhance its search engine capabilities. HDFS architecture is designed in a Java-based file system by Doug Cutting and Mike Cafarella.
Capabilities:
HDFS (Hadoop Distributed File System ) architecture has designed in such a way that it has excellent fault-tolerant and self-healing features. It enables Hadoop to harness the true capability of distributed processing techniques.
It is achieved by turning a cluster of industry-standard server or commodity servers into a massively scalable pool of storage.
Feature in its cap:
Just to add another feather in its cap, HDFS can store structured, semi-structured, or unstructured data in any format regardless of schema and is specially designed to work in an environment where scalability and throughput are critical.
Typical HDFS cluster:
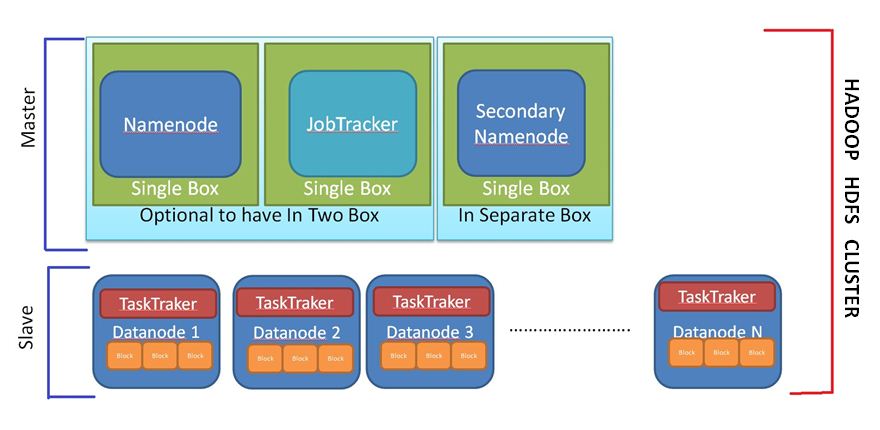
Nodes of Cluster:
The entire Hadoop HDFS cluster is divided into two parts.
Master:
This part of the cluster contains a node which is termed as Name Node. There can be one or two optional Node which can be used for fault tolerance purpose which is termed as Secondary / Standby Name Node.
Slave:
All servers which are a slave are called Data Node. The no of data node can be anything that suits the business requirements.
The size of data that can be held by HDFS in a cluster is decided by the data nodes disk size which is allocated in HDFS. Any additional storage requirement can be fulfilled by just adding one or more nodes of the required disk size.
Name node:
Metadata stored on Name node:
Because Name Node is the central piece of the entire HDFS cluster, it is essential to take good care of this node.
This machine is recommended to be a good quality server with having a lot of RAM. This is the node that keeps a mapping of “files to block” and “blocks to the data nodes”.
In short, the Name node stores the file system metadata.
Tasks performed by Name node:
This task is being done on Name nodes using two tables maintained in memory.
One of which is maintained for “Files to block mapping”. If there is any block corruption happens at the data node this table in memory gets updated on the Name node and action is taken accordingly.
The second table is maintained to track the mapping of “blocks to data nodes”. If any data node is not responding within the specified time, the name node update the second table, and action is taken based on this information.
Any communication by the client application to this cluster is always done using the name node.
Drawback of the HDFS cluster:
The name node is the heart of the this cluster. However, this becomes the Achilles’ heel of the entire cluster too. This is because if this machine got any failure, entire cluster does not have any clue where to go and what action needs to be taken.
SPOF(Single point of Failure):
In simple word, everything goes down with this one machine. This is termed as single point of failure (SPOF) .
Limitations posed by Name node:
Although, the cluster can accommodate more machines, however, addition of machine is somewhat limited by memory of the Name Node.
This may be a bottleneck beyond 4000 odd machines. This is because the name node stores all metadata in its memory.
The Solution:
Very soon, starting with version 2.0 and beyond, Hadoop came up with solutions to this. They devised a quick turnaround time for failover of name node.
Failover of name node:
To provide high availability of HDFS cluster, Hadoop devise the concept of active/passive configuration with a hot standby. This enables cluster adding additional name nodes in quickest possible failover time.
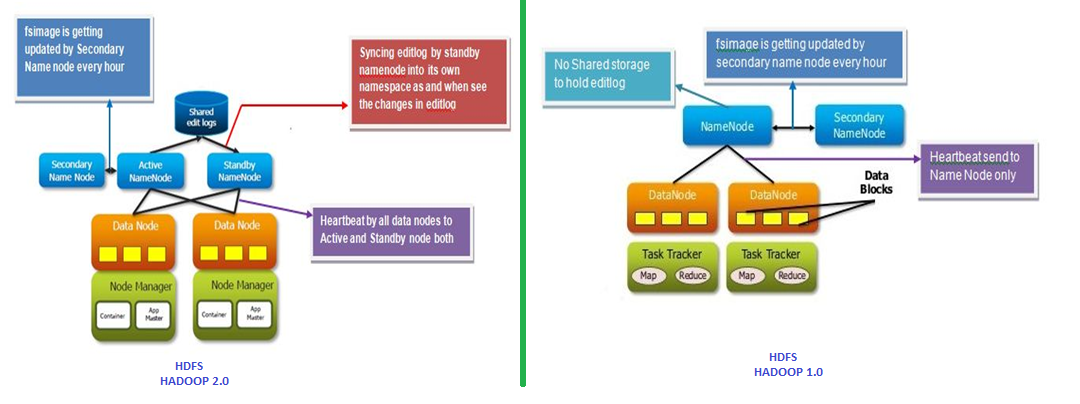
Hadoop 1.0 internals:
To understand the concept of Name Node (Active), Secondary Name Node and Standby Name Node (Passive), let’s understand the purpose of the secondary name node first.
There is one redundant node available which was known as secondary name node in both versions (1.0 and 2.0) of Hadoop
However, this is the only redundant node available in 1.0. Furthermore, this node was used in failover.
The challenge with this version is the failover could be possible only with the interference of the Hadoop administrator manually.
Hadoop 1.0 Metadata:
The file system metadata is maintained by HDFS on Name node with the help of two files.
- editlog:
This file is getting updated by Hadoop about each and every action taken by HDFS for example adding a new file, deleting a file, moving it between folders. Because it records all activity of HDFS, this file quickly grows a lot.
- fsimage:
HDFS read this file at the time of boot to understand the checkpoint status of the cluster.
Hadoop 1.0 Internals:
For successful startup of HDFS cluster these two files has to be in sync. Therefore, Hadoop writes all the new records of editlogs to fsimage first, just before starting up cluster.
Once this file syncing completed, HDFS reads the status of cluster from fsimage and start the cluster. The issue with this setup is that HDFS does synchronization of only at startup by name node.
Hadoop 1.0 Challenges:
Now consider a scenario where the name node is running for a month before we brought it down for maintenance.
Once maintenance completed and we try to start name node. This is the time when the editlog and the fsimage file synchronization process starts.
Hadoop 1.0 Huge down time:
Since name node was running for a month, the editlog size is very high and thus, it will require a lot of downtime to start the HDFS even if the maintenance time is very less.
Concept of secondary name node comes into picture to avoid this increased downtime.
Hadoop 2.0 Internals:
Hadoop 2.0 SN node’s Added Functionality :
This is really an improvement in HDFS architecture.
The function of secondary name node is to wake up and read the editlog from name nodes for new records created in the last one hour.
If changes found, it asks for existing fsimage from name node, reload it in its own namespace, update it and send it back to name node to reload it in the name node namespace.
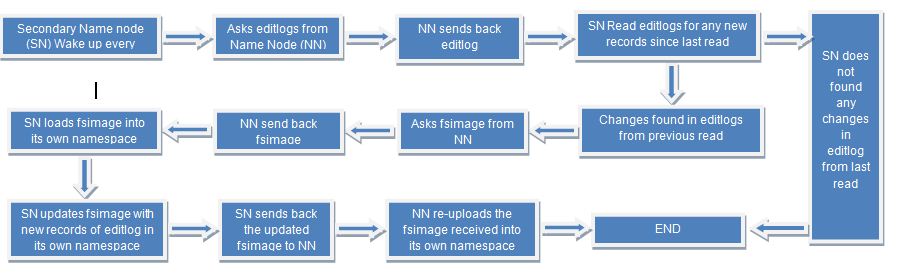
In the new high availability architecture, HDFS allowed us to add another name node which it calls as passive/standby name node.
Hadoop 2.0 Divide and Conquer :
It has devided the task of both secondary and standby name node.
Secondary nodes update the fsimage of the name node. Standby node performs reload fsimage into its own name space as and when it got updated.
Data nodes are communicating to both nodes using heartbeat instead of only name node in case of SPOF architecture.
Hadoop 2.0 Split-brain solution:
The restriction, here, is an only one name node can be active at a time. This restriction is imposed simply to avoid split-brain scenario. The namespace state would quickly diverge between the two and if both will be active it will be risking data loss or other incorrect results.
Hadoop 2.0 Journaling:
HDFS does this with the help of “Journal Nodes” which allow only one name node to write capability at a time.
File editlog is stored on shared storage to get accessed by standby name node at every point of time. As soon as failure occurs at Name node, standby name node took over the functionality of “Journal Nodes” and become active.
Hadoop 2.0 Failover with minimal downtime:
Rests are already in sync by standby name node, hence, the cluster proceeds with the current processing without any loss of data or incorrect result.
This shows the power HDFS architecture in processing big data. The fast processing the such huge data with minimal downtime is the objective.