Disadvantage of DWH:
Because of the limitation of currently available Enterprise data warehousing tools, Organizations were not able to consolidate their data at one place to maintain faster data processing.
Here comes the magic of hadoop for their rescue.
Traditional ETL tools may take hours, days and sometimes even weeks. And because of this, performances of these tools are limited by two Hardware limitations.
Limitations:
- The vertical hardware scalability: Hardware can be scaled vertically to one extent beyond which no further addition is possible.
For example, if the required RAM can be scaled to 64 GB or so, but even this is having some limitation and beyond that no RAM can be added. - Hardware Failure: In this structure of hardware, failure of even a small component can lead the down of entire processing.
Magic of Hadoop:
With the use of distributed parallel processing design magic of Hadoop overcome these scenarios. And this can be configured using low cost commodity machines. This technique relies on horizontal scaling of hardware.
Horizontal scaling can be achieved by adding new commodity machines without any limitations.
Above all, the best part of this type of hardware is fault tolerant and can accommodate one or more machine failure without much performance hit.
Magic of distributed parallel processing:
By harnessing the true capability of distributed parallel processing Hadoop enables organization to decentralize its data. It allow them to capture data at very low granular level.
It also helps them speeds up their data processing on decentralized data to the maximum.
By enabling Hadoop an organization, with huge data, can get its analysis within minute for which it was waiting for hours in traditional ETL with very less data.
Making Organization’s life easy:
Hadoop makes it easier to collect all the data of all the times without even concerning about their size and processing performance.
It also helps organization analyze these data in no time the way they require to improve the business performance of the organization.
Hadoop’s core components:
Hadoop is performing all this magical job with the help of its four core components which makes its architecture an elegant design. These components can be listed as below.
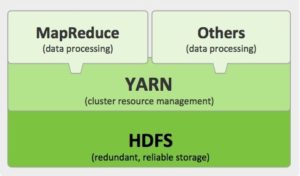
HDFS (Hadoop Distributed File System):
This file system lays the foundation of Hadoop. It provides reliable data storage across all the nodes of a cluster of Hadoop.
HDFS is connects all the nodes of a cluster in such a way that the storage spread across machine is treated as one single storage.
This file system links together all nodes of a cluster and make them a single file system. Adding a new Machine in this cluster is just like increase the storage space.
YARN (Yet Another Resource Negotiator):
What HDFS does at storage side, YARN does at CPU and memory side. YARN does the same thing with CPU and Memory.
It works like an operating system in Hadoop like Monitor and manages workloads and implementing security.
It also helps controlling, and managing high availability features of Hadoop.
MapReduce:
This programming paradigm is the heart of Hadoop which facilitates tremendous scalability across hundreds or thousands of servers in a Hadoop cluster.
It is actually a combination of two separate and distinct tasks (MAP and REDUCE) .
This makes Hadoop takes the large data set, spread it across multiple nodes of Hadoop, get the processed results and combine the results to return it to the user in quickest manner.
Hadoop common:
This module contains the utilities that support the other Hadoop components to work or interact with each other.
1 thought on “Magic of Hadoop”