Distinct is the keyword that oracle used to filter out unique values from a column. However, it is very interesting to see the behavior followed by the optimizer for its access path.
How Oracle Index Fast Full Scan Handles DISTINCT Queries?
In this “Optimizer Access Paths” blog, we will see how we can make optimizer to use an index with a distinct keyword.
Watching the Oracle index fast full scan distinct behavior in action is one of the cleanest ways to understand why proper indexing matters for unique value queries.
Let’s understand this with an example. We will use a query on the emp table to understand this better.
Query: select distinct job from emp;
Index: create index idx_emp_job on emp(job);
The explain plan for this query in both scenarios i.e. Pre-Index and Post-Index are similar where we do not see any changes.

Pre-Index Plan
Post-Index PlanIt is rather interesting to see that there are no changes in access path behavior, however, it is the very desired behavior of the optimizer here in this scenario.
When oracle create B-Tree index, it does not include any value which is null in the column. Hence, there are no way where optimizer can figure out that there are any NULL value in the column using index only. To figure this out, optimizer have to look into the table itself and this induce “Full table scan“.
So, is there any way we can induce the index?
We can of course make optimizer to use the index for this query only if optimizer already know that it does not have to look into for any NULL value. This can be achieved if we make the column in question as not null by altering the table.
Statement: alter table emp modify job not null;
With this, the optimizer does know that there are no rows that would be having NULL values and the optimizer changes its access path to use the index.
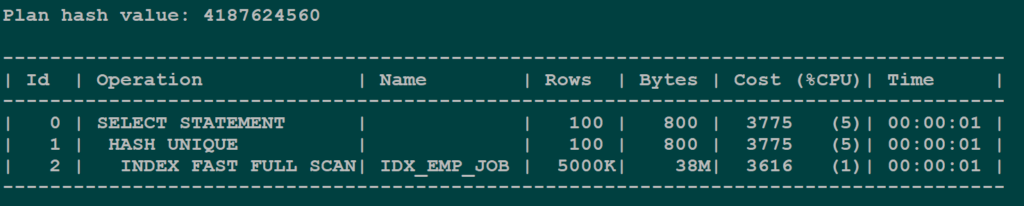
Post Alter using Index PlanThis is how we can tell the optimizer that it should use the index where a distinct keyword is used in the query.
1 thought on “Optimizer Access Paths: How Index FFS works with Distinct”