
By Sanjeeva Kumar | Senior Oracle DBA & Database Architect
Published: February 2026 | Reading time: 8 minutes
The Scaling Advice That’s Costing You Millions
OpenAI is running 800 million ChatGPT users on unsharded PostgreSQL. One primary writer per cluster. 50+ read replicas. No Cassandra. No sharding. Just PostgreSQL — properly governed.
Sound familiar? It shouldn’t. Because everything you’ve been told about “mandatory sharding at scale” is wrong.
Most of you are planning to shard your databases way too early.
If you’re reading this because your application hit 5 million users and every scaling guide is screaming “SHARD NOW!”, stop. Take a breath. Let me tell you about OpenAI.
They’re running 800 million ChatGPT users on unsharded PostgreSQL clusters. Each production cluster: one primary writer, dozens of read replicas, millions of queries per second.
Let me be precise here: OpenAI operates multiple PostgreSQL clusters for workload isolation—but each individual cluster is intentionally kept unsharded. They avoid the complexity of cross-shard queries, not the isolation benefits of separate databases.
No sharding within clusters. No exotic distributed database. Just PostgreSQL, properly optimized and intelligently separated.
At PGConf.dev 2025, Bohan Zhang from OpenAI’s infrastructure team shared their PostgreSQL journey. As I watched that presentation, I realized they’re breaking every “mandatory” scaling rule that textbooks preach. And they’re succeeding spectacularly.
Let me show you which myths they shattered—and what we DBAs should actually focus on instead.
Myth #1: “You Must Shard Beyond 10M Users”
The Textbook Says: Once you hit 10-50 million users, horizontal sharding is inevitable. Split your data across multiple database nodes.
OpenAI’s Reality: 800 million users across multiple PostgreSQL clusters. Each cluster: single primary writer, zero sharding.
Why It Works: OpenAI uses multiple clusters for workload isolation (ChatGPT production, internal tools, analytics), but keeps each cluster architecturally simple. Their workload is read-heavy (like most modern applications). They scale reads with replicas, not sharding. Their secret isn’t splitting data—it’s optimizing the bottleneck and using cluster-level isolation instead of shard-level complexity.
The Real Question: What’s Your Write Percentage?
I’ve seen teams shard prematurely because they followed generic advice. They had 95% reads, 5% writes—but invested six months building sharding infrastructure for a write problem they didn’t actually have.
Before you shard, answer this:
- What’s your read vs. write ratio?
- Can you offload writes to async queues?
- Can you cache more aggressively?
- Have you optimized your connection pooling?
OpenAI did all of this first. Sharding was their last resort, not first move.
Myth #2: “Connection Pooling Is Optional”
The Textbook Says: Connection pooling is a performance optimization—nice to have, but not critical.
OpenAI’s Reality: PgBouncer was mission-critical. Without proper connection pooling, their PostgreSQL cluster would’ve collapsed under connection pressure.
The Idle Transaction Disaster
OpenAI shared something every DBA should pin to their wall:
Idle transactions are silent killers.
Applications that open connections, start transactions, then do unrelated work (API calls, processing, waiting) before committing—these kill database performance. They hold connections hostage. They block schema changes. They create replication lag.
At OpenAI, the engineering team implemented compile-time checks in their Rust codebase to prevent awaiting async functions while holding PostgreSQL connections. That’s how serious they are about connection discipline.
My Take: Connection Pooling is Governance
Connection management is database governance. It’s not a performance tweak—it’s a fundamental architectural decision.
If you’re not using PgBouncer (or Oracle DRCP, or MySQL ProxySQL), you’re gambling with your database’s stability.
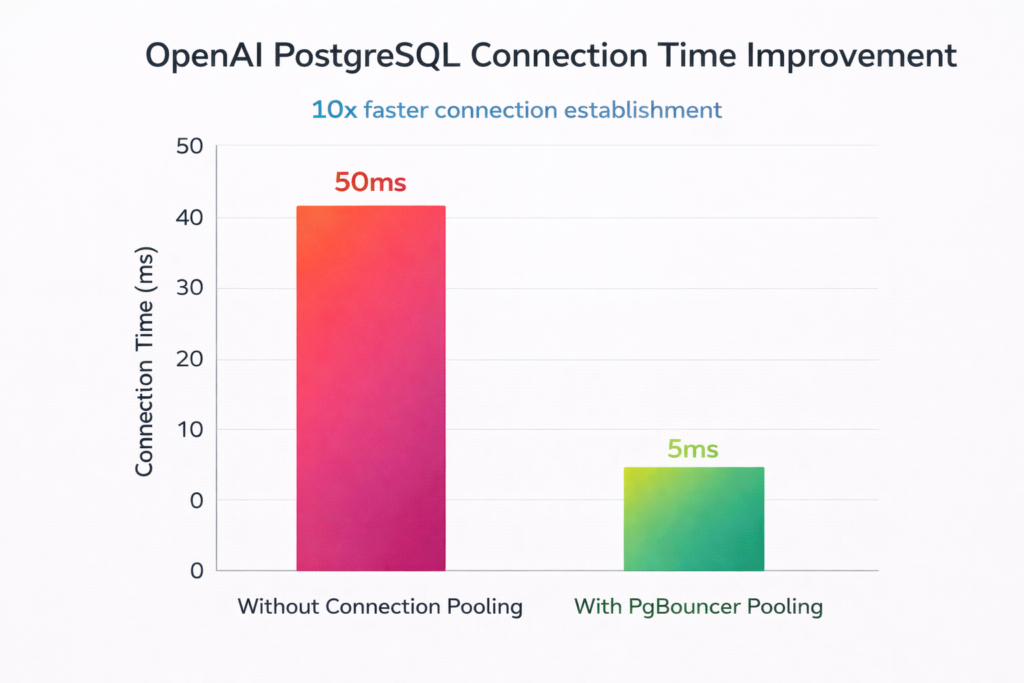
OpenAI’s configuration:
- Transaction-level pooling
- Aggressive timeout policies
- Monitoring connection saturation religiously
- Application-level enforcement of connection discipline
This isn’t optional. This is table stakes for scale.
Myth #3: “Read Replicas Have Limits”
The Textbook Says: You can have maybe 5-10 read replicas before replication lag becomes unmanageable.
OpenAI’s Reality: 50+ read replicas globally. Including cross-region replicas for low latency worldwide.
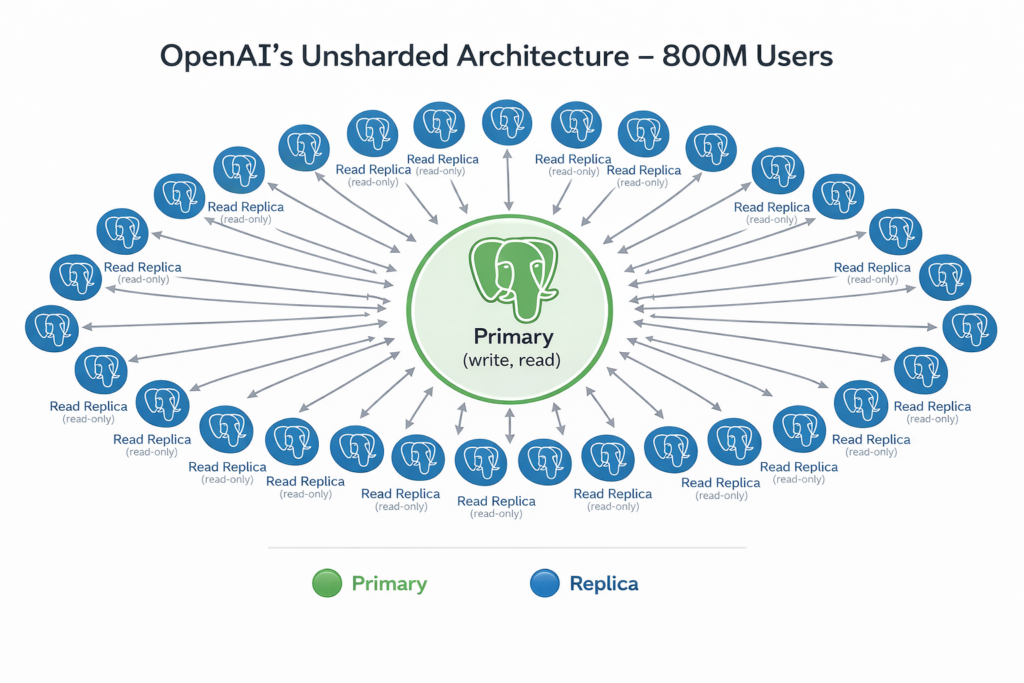
The Breakthrough: They didn’t just add replicas randomly. They architected for it:
Dedicated Replicas for Priority Workloads
OpenAI’s architecture combines two isolation strategies:
Cluster-level isolation: Different PostgreSQL clusters for different services (ChatGPT production, analytics, internal tools)
Replica-level isolation within each cluster: High-priority vs. low-priority read workloads get dedicated replicas
This dual-layer approach is brilliant:
- Critical ChatGPT queries → Dedicated replicas in production cluster
- Background analytics → Separate replica set (or entirely separate cluster)
- Internal tools → Another isolated environment
You’re not just scaling capacity—you’re scaling quality of service at both architectural levels.
Cascading Replicas (Azure Feature)
Azure Database for PostgreSQL introduced cascading replicas—replicas of replicas. This reduces load on the primary’s WAL senders and distributes replication work hierarchically.
Why this matters: In traditional setups, every replica connects to the primary. At 50+ replicas, that’s 50 replication connections on your primary. Cascading solves this.
Myth #4: “Schema Changes Are Always Risky”
The Textbook Says: Minimize schema changes in production. They’re inherently dangerous.
OpenAI’s Reality: Schema changes are safe when governed properly. They have strict rules—and they’re surgical about it.
OpenAI’s Schema Change Governance (4 Rules)
Rule 1: No new tables or workloads on the cluster
Don’t expand scope. Protect what’s already there.
Rule 2: Column changes allowed, but with 5-second timeout
Adding/dropping columns is fine. But anything requiring full table rewrite? Blocked.
Rule 3: Indexes must use CONCURRENTLY
Never lock tables during index creation. Period.
Rule 4: Optimize or move long-running queries (>1 second)
Long queries block schema changes. Applications must offload them to replicas.
This is Database Governance in Action
As someone working on AI Governance frameworks, I see this as a perfect example: Governance isn’t bureaucracy—it’s intelligent constraints that enable velocity.
OpenAI doesn’t say “no schema changes.” They say “schema changes under these conditions.” That’s mature engineering.
Compare this to organizations where every schema change requires a 3-hour CAB meeting and 2-week freeze windows. OpenAI proves you can move fast AND stay safe.
Myth #5: “Managed Services Limit Scale”
The Textbook Says: If you want extreme scale, you need self-hosted infrastructure with total control.
OpenAI’s Reality: Azure Database for PostgreSQL. Fully managed. Millions of QPS.
Now, Bohan was honest—managed services do impose constraints. Storage limitations, replication configurations, extension restrictions. These are real.
But look at the tradeoff:
- Zero database maintenance overhead
- Automated backups and high availability
- Elastic scaling when needed
- Microsoft’s PostgreSQL team as partners
OpenAI chose to invest engineering effort in application optimization, not database operations. That’s a strategic choice.
When Self-Hosting Makes Sense
The PIGSTY project author commented on OpenAI’s talk: “We run 2.5M QPS on self-hosted PostgreSQL with local NVMe SSDs.”
Both approaches work. The question is: Where do you want to invest your DBA talent?
- Infrastructure management? → Self-host
- Application optimization? → Managed service
There’s no universal answer. But OpenAI proved managed services can absolutely handle massive scale.
The Real Bottleneck: Writes, Not Reads
OpenAI was brutally honest: Write requests are their bottleneck.
All writes funnel through the single primary. That’s the architectural constraint. Everything else is tactics around this reality.
Their Write Optimization Strategy:
1. Offload Writes Wherever Possible
- Queue writes asynchronously
- Batch operations
- Cache write-through where appropriate
2. Prohibit New Services on Primary
- New workloads go to different databases
- Don’t compound the bottleneck
3. Monitor Write Amplification from Indexes
- Every unused index adds write overhead
- They want a “disable index” feature to test before dropping
4. Optimize for PostgreSQL’s MVCC Reality
- Every write creates a new tuple version
- Dead tuples cause bloat
- Aggressive vacuuming is critical
- Monitor table and index bloat constantly
This is Real DBA Work
Not cutting-edge. Just solid, practical database engineering.
I’ve seen Oracle shops with similar challenges. Same principles apply:
- Know your bottleneck
- Optimize relentlessly at the bottleneck
- Don’t solve problems you don’t have
The Incident That Changed Everything
OpenAI shared two production incidents that reshaped their approach:
Incident 1: Redis Cascade Failure
When Redis went down, application code fell back to hitting PostgreSQL directly. This created a cascading failure—suddenly, thousands of uncached queries slammed the database.
The Fix: Circuit breakers. Graceful degradation. Never let application failures cascade to the database.
Incident 2: WALSender Spin Loop
During high CPU load, a PostgreSQL bug caused WALSender processes to spin-loop instead of sending WAL to replicas. Even after CPU normalized, the spin loop continued—causing replication lag to spike.
The Fix: Better observability. Monitoring CPU patterns correlated with replication lag. Proactive alerts before lag impacts users.
What I Love About This
OpenAI didn’t hide their failures. They shared them publicly. That’s engineering maturity.
Every DBA has war stories. The difference between good and great teams is whether they learn systematically from incidents.
What Should You Actually Do?
If you’re a DBA or architect reading this, here’s my advice based on 20 years of scaling databases—and OpenAI’s validation:
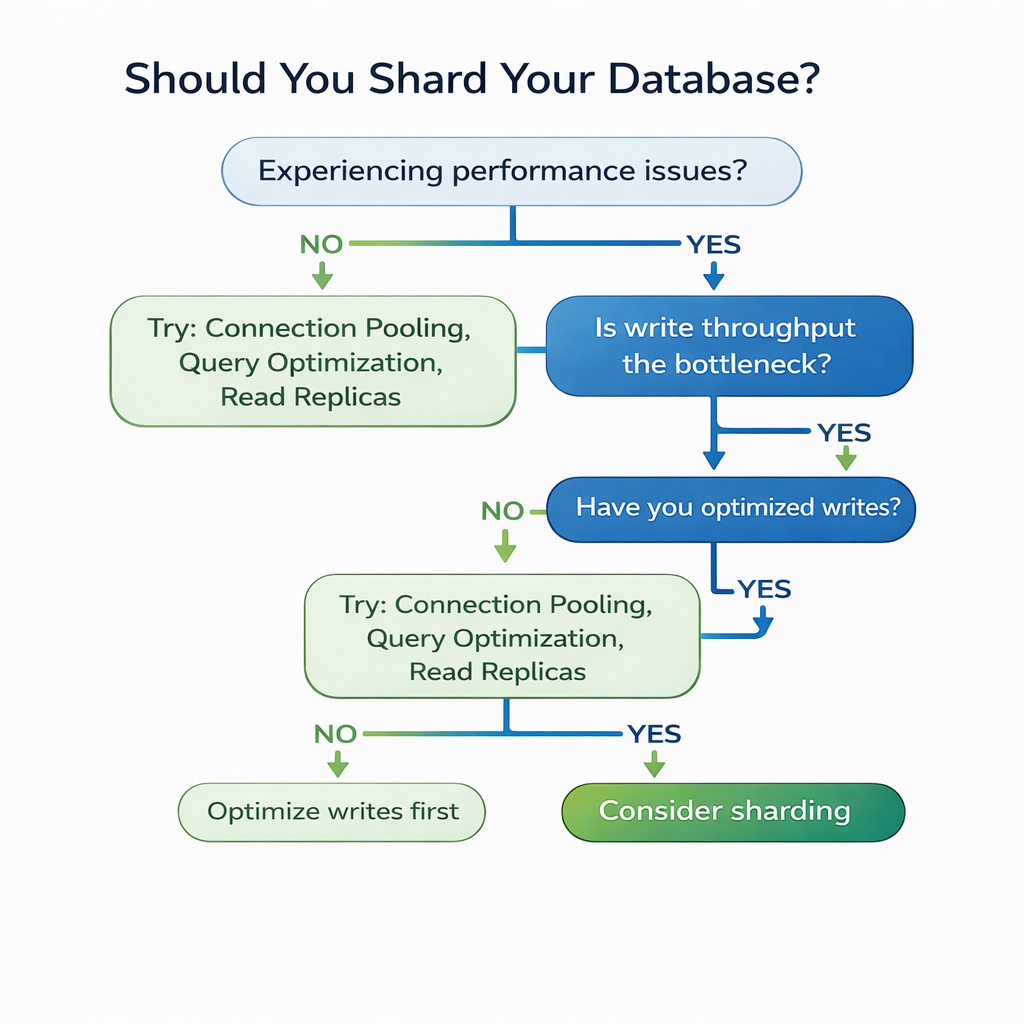
1. Measure First, Shard Later
Before you shard:
- Profile your read/write ratio
- Measure your actual bottleneck
- Try connection pooling
- Optimize queries
- Add read replicas
- Cache aggressively
Only shard when:
- Write throughput is genuinely maxed out
- Single-primary can’t handle your write load
- You’ve exhausted all optimization options
2. Invest in Connection Pooling NOW
PgBouncer for PostgreSQL. DRCP for Oracle. ProxySQL for MySQL.
This isn’t optional. This is foundational.
Configure it properly:
- Transaction-level pooling for OLTP
- Aggressive timeouts
- Monitor connection saturation
- Enforce application-level connection discipline
3. Separate Read Workloads by Priority
Don’t treat all reads equally. OpenAI’s dedicated replica approach is genius:
- Customer-facing queries → Fast replicas
- Analytics → Separate replica set
- Internal tools → Yet another set
This is query-level governance.
4. Govern Schema Changes, Don’t Fear Them
Adopt OpenAI’s 4 rules:
- No new workloads on critical clusters
- Column changes with timeouts
- CONCURRENTLY for all indexes
- Move long-running queries off primary
5. Monitor Write Amplification
Every index has a cost. Review your indexes:
- Are they all used?
- Can you consolidate?
- Are covering indexes worth the write overhead?
6. Build Observability Into Everything
OpenAI’s reliability improved dramatically with better monitoring:
- Query performance (pg_stat_statements)
- Replication lag
- Connection saturation
- CPU patterns correlated with database health
- Cache hit ratios
You can’t optimize what you don’t measure.
The Bigger Picture: AI and Database Engineering
Here’s why this matters beyond just PostgreSQL scaling:
AI workloads are database-intensive.
ChatGPT’s success depends on PostgreSQL’s reliability. When the database goes down, ChatGPT goes down. The AI models are impressive, but they’re useless without solid data infrastructure.
This is why I’m passionate about AI Governance from a DBA perspective. Everyone talks about model governance, fairness, explainability. But who’s talking about the data layer?
- How do you govern training data lineage?
- How do you ensure observability for AI inference queries?
- How do you manage schema changes for vector databases?
- How do you handle the write amplification from embedding updates?
AI Governance should include database governance. OpenAI proves this.
I’m working on a framework that bridges traditional DBA practices with AI system requirements. If you’re interested, let me know in the comments—I’ll share more in upcoming posts.
Key Takeaways for DBAs
🎯 Stop following generic scaling advice. OpenAI serves 800M users on unsharded PostgreSQL. Your 10M user app doesn’t need sharding yet.
🔌 Connection pooling is non-negotiable. It’s not optimization—it’s architecture. Implement it properly or pay the price later.
📊 Reads scale easily, writes don’t. Focus your energy on the actual bottleneck. Most applications can scale reads to billions with replicas.
🛡️ Governance enables velocity. OpenAI’s schema change rules prove that smart constraints let teams move faster, not slower.
👁️ Observability is your competitive advantage. You can’t optimize what you don’t measure. Build comprehensive monitoring from day one.
💾 Managed services can absolutely scale. Don’t let “we need control” bias push you toward self-hosting unless you’ve done the cost analysis.
What’s Next?
In upcoming posts, I’ll dive deeper into:
- Connection pooling deep dive: PgBouncer vs DRCP vs ProxySQL comparison
- Schema migration governance: Building OpenAI-style rules for Oracle and PostgreSQL
- Write optimization strategies: Tackling the single-primary bottleneck
- AI Governance for DBAs: Bridging database practices with AI system requirements
About the Author
Sanjeeva Kumar is a Senior Oracle DBA and Associate Principal Engineer at Nagarro Software with over 20 years of database administration experience. He specializes in PostgreSQL, Oracle, and MySQL, focusing on performance optimization, architecture design, and database governance. He writes about database engineering and AI systems at dbadataverse.com.
1 thought on “PostgreSQL Scaling: What OpenAI Proved Wrong at 800M Users”