Last Updated: December 2025 | By Sanjeeva Kumar | 20+ Years in Database Systems
The Plot Twist Nobody Saw Coming
Two weeks ago, PostgreSQL’s pgvector extension released version 0.8.0. Within days, the entire vector database market collectively held its breath.
Why? Because that “old guard” relational database just made billion-dollar vector database startups look like expensive overkill.
Remember when everyone said you needed Pinecone, Weaviate, or Milvus for AI workloads? The PostgreSQL vs vector database narrative was clear: specialized tools for specialized problems. When every startup pitch deck had “powered by [insert specialized vector DB]” on slide three? When Pinecone raised $138 million and achieved unicorn status?
TCO estimates based on mid-sized deployments (1M–50M vectors, 10K–100K queries/day). At low query volumes, serverless pricing models (e.g. Pinecone’s per-read/write unit) can reduce the gap. Verify current vendor pricing before budgeting.
That narrative is crumbling. Fast.
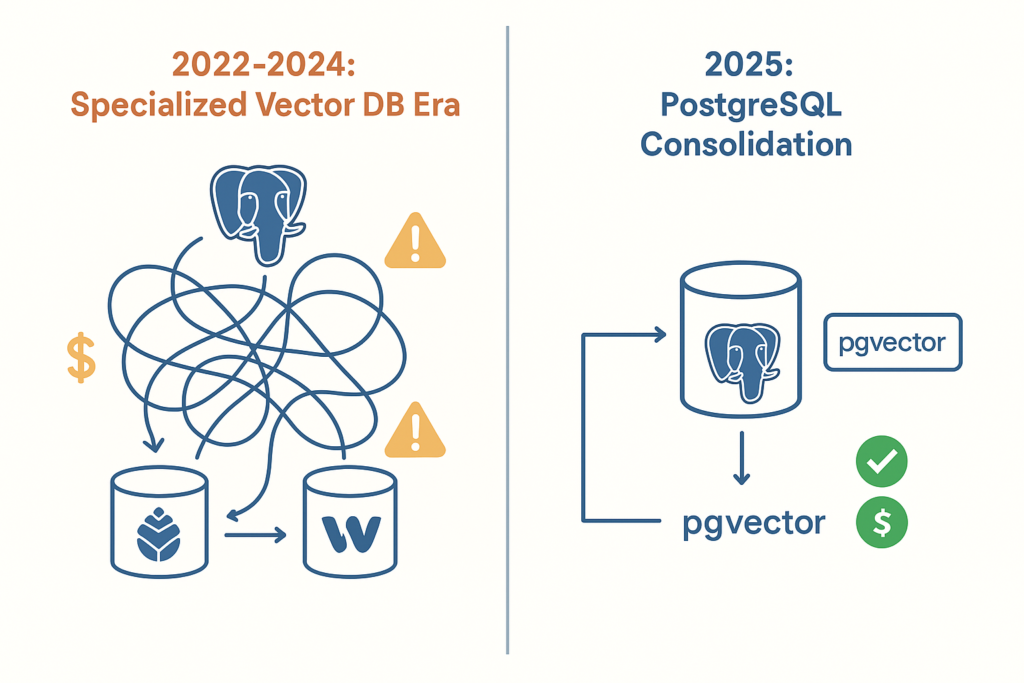
As a DBA with over 20 years managing production databases, I’ve watched this story unfold with a mix of amusement and vindication. The vector database gold rush of 2022-2024 is experiencing what I call “the great consolidation” – and PostgreSQL is winning.
Not because it’s newer. Not because it’s fancier. But because it solves the actual problems DBAs face in production.
The Vector Database Gold Rush (2022-2024)
When ChatGPT exploded in late 2022, enterprises suddenly needed somewhere to store embeddings for Retrieval-Augmented Generation (RAG). Vector databases promised to solve this “new” problem.
The pitch was seductive:
- “Purpose-built for AI workloads”
- “Optimized for high-dimensional vectors”
- “Lightning-fast similarity search”
- “Built for the AI era”
The reality? A different story.
Specialized vector databases emerged as single-purpose solutions to what they claimed was a fundamentally new problem. But as any experienced DBA knows, new problems rarely require entirely new databases. They require mature databases with new capabilities.
The market saw massive investment:
- Pinecone: $138M raised, $750M valuation
- Weaviate: Unicorn status
- Milvus, Chroma, Qdrant: Hundreds of millions in funding
But here’s what the marketing didn’t tell you:
- Most “AI-native” vector databases are just specialized indexes with a sleek API
- They introduced operational complexity teams weren’t prepared for
- They created data silos that violated every data architecture principle
- They added vendor lock-in to what should be commodity infrastructure
Why PostgreSQL vs Vector Database Isn’t Even Close
1. Economic Reality: Total Cost of Ownership
Specialized Vector Database TCO:
Monthly Costs (Mid-sized deployment):
- Database service: $500-2,000/month
- Separate PostgreSQL instance: $200-800/month (still needed for metadata)
- Data sync infrastructure: $300-600/month
- Engineering overhead: 20-40 hours/month
Annual TCO: $18,000-50,000+PostgreSQL with pgvector TCO:
Monthly Costs (Same workload):
- Single PostgreSQL instance: $300-1,200/month
- pgvector extension: $0 (open source)
- Data sync infrastructure: $0 (eliminated)
- Engineering overhead: 5-10 hours/month
Annual TCO: $3,600-15,000
Cost Reduction: 60-80%Competitor pricing as of December 2025 — Pinecone, Weaviate, and Milvus pricing changes frequently. Verify at official pricing pages before making infrastructure decisions.
As a DBA, this math is obvious. You’re paying 3-5x more to maintain two databases instead of one, plus the hidden costs of keeping them synchronized.
2. Operational Simplicity (The Real Game Changer)
Traditional RAG architecture with specialized vector DB:
1. User data enters PostgreSQL
2. Application extracts text for embedding
3. Generate embeddings via API
4. Write embeddings to vector DB
5. Write metadata to PostgreSQL
6. Maintain synchronization between both
7. Handle consistency issues
8. Monitor two separate systems
9. Backup two separate systems
10. Scale two separate systems independentlyPostgreSQL + pgvector architecture:
1. User data enters PostgreSQL
2. Generate embeddings via API
3. Store embeddings in same database
4. Done.Six fewer operational steps. Six fewer failure points. One monitoring stack. One backup system. One disaster recovery plan.
This is not a minor advantage. In production, complexity is the enemy. Every additional system is a potential 3 AM wake-up call.
3. Technical Parity (The Surprise)
The dirty secret? pgvector performance is now competitive with specialized solutions.
pgvector 0.8.0 benchmarks (December 2025):
- HNSW indexing matches dedicated vector DB performance
- Sub-50ms query latency for millions of vectors
- Efficient indexing up to 4,000 dimensions (half-precision)
- Binary quantization supports up to 64,000 dimensions
- Up to 67x faster index builds with pgvector 0.7.0+
Translation for DBAs: For 80% of real-world AI workloads, PostgreSQL is fast enough. The remaining 20% don’t justify rebuilding your entire data infrastructure.
Reality check: Most applications don’t have billions of vectors. Most don’t need sub-10ms latency. Most need accurate results from a maintainable system.
PostgreSQL delivers that. With 30+ years of production hardening.
4. Ecosystem Maturity (The Underrated Factor)
What specialized vector databases give you:
- Novel APIs to learn
- Limited tooling ecosystem
- Smaller talent pool
- Uncertain long-term viability
What PostgreSQL gives you:
- SQL (every developer knows this)
- Decades of battle-tested tools
- Massive DBA talent pool
- pgAdmin, Postgres.app, countless extensions
- Every major cloud provider offers managed PostgreSQL
- 30+ years of production stability
As someone who’s hired DBAs for two decades, this matters. Finding a PostgreSQL expert takes days. Finding a Weaviate expert? Good luck.
5. Hybrid Search (The Killer Feature in PostgreSQL vs Vector Databases)
Here’s where PostgreSQL absolutely demolishes specialized solutions: combining vector search with traditional queries.
Real-world query with PostgreSQL:
sql
-- Find similar products that are:
-- 1. In stock
-- 2. Under $50
-- 3. 4+ star rating
-- 4. Semantically similar to search query
SELECT p.product_id, p.name, p.price, p.rating,
p.embedding <-> query_embedding AS similarity
FROM products p
WHERE p.in_stock = true
AND p.price < 50
AND p.rating >= 4.0
ORDER BY p.embedding <-> query_embedding
LIMIT 20;Same query with specialized vector DB:
Step 1: Query vector DB for similar items
Step 2: Get list of IDs
Step 3: Query PostgreSQL with those IDs
Step 4: Filter by price, stock, rating
Step 5: Handle consistency issues (what if data changed?)
Step 6: Merge results in application layerPostgreSQL does it in ONE query. One network round-trip. One transaction. Guaranteed consistency.
This is the real advantage: Your AI features integrate seamlessly with your existing data model. No impedance mismatch. No data synchronization hell.
PostgreSQL vs Vector Database: When PostgreSQL Wins (90% of Cases)
PostgreSQL with pgvector is the right choice when:
1. You Already Use PostgreSQL
If your application data lives in PostgreSQL, adding pgvector is a no-brainer. You’re already paying for PostgreSQL – just enable the extension.
2. You Need Hybrid Search
Any use case requiring vector similarity PLUS traditional filters, joins, or aggregations. This covers most real-world scenarios:
- E-commerce search
- Content recommendation
- Document retrieval
- Customer support AI
3. Your Scale Is “Normal”
- < 100M vectors
- < 1,000 queries per second
- Latency requirements > 20ms
- Growth patterns measurable in months, not hours
Reality check: This describes 90% of production AI applications.
4. You Value Operational Simplicity
If you’re a lean team (and who isn’t?), every additional system multiplies operational burden. PostgreSQL + pgvector means:
- One database to backup
- One database to monitor
- One database to scale
- One database to debug at 3 AM
5. You’re Building an MVP or Prototype
Start with PostgreSQL. Even if you think you’ll “need” a specialized vector DB later, proving value first is smart strategy. PostgreSQL gets you to production faster.
Migration path exists: If you truly outgrow PostgreSQL (rare), you can migrate later. But most companies never will.
Firecrawl switched from Pinecone to Supabase (a managed PostgreSQL platform) — not self-managed PostgreSQL, but the consolidation signal is identical: one database stack, no sync layer.
When Specialized Vector DBs Still Make Sense (10% of Cases)
I’m not saying specialized vector databases are useless. They have legitimate use cases. The PostgreSQL vs vector database equation changes at extreme scale.
Consider a specialized vector database when:
1. Massive Scale
- 1B+ vectors
- 10,000+ QPS
- Sub-10ms latency requirements
- Multiple geographic regions
Examples: Google-scale search, global recommendation engines, real-time fraud detection at banking scale.
2. Advanced Indexing Requirements
- GPU-accelerated search
- Product quantization at scale
- Sparse vector support
- Streaming ingestion pipelines
3. AI-Native Product Focus
If your ENTIRE product is built on vector similarity (like image search engines, advanced recommendation systems), specialized infrastructure might be justified.
But be honest: Is that really your use case? Or are you over-engineering?
4. Team Has Vector DB Expertise
If your team already operates Milvus or Weaviate in production, has battle-tested deployment patterns, and knows the failure modes – maybe stick with what works.
But for new projects? Start with PostgreSQL.
The Strategic Implications for DBAs: PostgreSQL vs Vector Database Decision Framework
This isn’t just about technology. It’s about architecture philosophy and the PostgreSQL vs vector database choice that defines your AI infrastructure.
The Death of “Use the Right Tool for the Job” Absolutism
For years, we’ve been told to use “the right tool for the job.” This led to:
- Polyglot persistence nightmares
- 10+ databases per application
- Data synchronization hell
- Operational chaos
The pendulum is swinging back. The “right tool” is often the one you already operate reliably. Adding pgvector to PostgreSQL is using the right tool – because it’s the tool you already know.
The Re-Bundling Trend
We unbundled databases in the 2000s (NoSQL revolution). We specialized further in the 2020s (vector databases). Now we’re re-bundling.
Why? Because operational complexity costs more than performance gains.
PostgreSQL can handle:
- OLTP workloads
- Analytics (with proper indexing)
- JSON documents (JSONB)
- Full-text search
- Geographic data (PostGIS)
- Time-series data (TimescaleDB)
- Vector embeddings (pgvector)
This isn’t a weakness – it’s a superpower. One mature, reliable platform for most workloads.
Risk Mitigation Through Proven Technology
Ask yourself:
- Would you bet your production system on a 2-year-old startup database?
- Or on PostgreSQL with 30+ years of production hardening?
I know which one I’d choose at 3 AM when things break.
Real-World Validation: The Market Is Speaking
Evidence of the shift:
1. Cloud Provider Investment
- AWS: Aurora PostgreSQL with pgvector 0.8.0 (April 2025), 67x faster embeddings load (October 2024)
- Google Cloud: AlloyDB with pgvector + ScaNN index support (8x faster index creation, 4x faster queries)
- Azure: PostgreSQL with pgvector
- Supabase: Built entire business on PostgreSQL + pgvector
Translation: Every major cloud provider is betting on PostgreSQL for AI workloads.
2. Enterprise Adoption
- Instacart: Migrated from Elasticsearch to PostgreSQL + pgvector (May 2025)
- Result: Simpler architecture, 80% cost savings on storage/indexing, 6% reduction in zero-result searches
- Revenue Impact: Substantial incremental revenue from improved search
Pattern: Large-scale companies with sophisticated teams are MOVING TO PostgreSQL, not away from it.
3. Developer Mindshare
- pgvector: 10,000+ GitHub stars
- Active development, monthly releases
- Integration with every major AI framework
- LangChain, LlamaIndex native support
The developer community has spoken: PostgreSQL is the pragmatic choice.
The DBA’s Decision Framework
Here’s how I’d evaluate this as a DBA:
Questions to Ask:
1. Do we already run PostgreSQL in production?
- Yes → Start with pgvector
- No → Maybe evaluate specialized options
2. What’s our vector scale?
- < 10M vectors → PostgreSQL is perfect
- 10-100M vectors → PostgreSQL can handle it
- 100M+ vectors → Consider specialized, but test PostgreSQL first
3. What’s our latency requirement?
- 50ms → PostgreSQL easily
- 20-50ms → PostgreSQL with proper indexing
- < 20ms → Maybe specialized, but benchmark first
4. Do we need hybrid search?
- Yes → PostgreSQL is dramatically simpler
- No → Still probably PostgreSQL for operational simplicity
5. What’s our team’s expertise?
- PostgreSQL → Obvious choice
- Vector DB → Can you justify the learning curve?
6. What’s our operational maturity?
- Small team → PostgreSQL (less complexity)
- Large SRE team → Maybe specialized if justified
- Startup → Definitely PostgreSQL (faster to production)
The Bottom Line: Pragmatism Over Hype
After 20+ years managing databases, I’ve learned one lesson: The best database is the one you can operate reliably at 3 AM.
Specialized vector databases had a moment. They solved a perceived problem with specialized tools. But the market is realizing that the real problem wasn’t lack of specialized databases – it was lack of vector support in PostgreSQL.
pgvector solved that.
The vector database “revolution” is over. PostgreSQL won. Not through marketing, but through pragmatism:
- Lower TCO
- Simpler operations
- Technical parity for most use cases
- Hybrid search capabilities
- 30 years of production hardening
- Massive ecosystem and talent pool
For the majority of enterprise AI workloads — everything below billion-scale vector counts and without pure-vector-only SaaS requirements — PostgreSQL + pgvector is the right answer.
The real question isn’t “Can PostgreSQL handle AI workloads?”
It’s “Why would you add complexity when you don’t need to?”
Key Takeaways
For DBAs evaluating AI infrastructure:
- Start with PostgreSQL + pgvector – Prove your use case before adding complexity
- TCO matters more than benchmarks – 60-80% cost reduction is real money
- Operational simplicity is a feature – One database beats two databases
- Hybrid search is the killer app – Combining vector + traditional queries in one transaction
- Specialized DBs have niche value – But “niche” means < 10% of real workloads
- The market is consolidating – Every major cloud provider bets on PostgreSQL + pgvector
- Trust production-hardened technology – 30 years of PostgreSQL > 2 years of vector DB startups
The pragmatic path: Start with PostgreSQL. Ship your MVP. Prove value. Scale vertically. If you truly outgrow it (rare), migrate later.
Most companies never will.
What’s Your Experience?
I’ve made my case from a DBA’s perspective. But every organization is different.
Questions for discussion:
- Have you deployed specialized vector databases in production?
- What were the operational challenges?
- Have you evaluated PostgreSQL + pgvector?
- What’s stopping you from consolidating?
Share your experience in the comments. The best architecture decisions come from real production experience, not marketing hype.
References & Further Reading
Cloud Provider Announcements
AWS Aurora PostgreSQL:
- Announcing pgvector 0.8.0 support in Aurora PostgreSQL (April 2025)
- Load vector embeddings up to 67x faster with pgvector 0.7.0 (October 2024)
- Aurora PostgreSQL adds pgvector for vector storage (July 2023)
Google Cloud AlloyDB:
- Unlock the power of gen AI with pgvector (June 2023)
- AlloyDB AI with ScaNN index support (January 2025) – 8x faster index creation, 4x faster queries
- AlloyDB for PostgreSQL release notes – pgvector versions 0.6.0, 0.7.0, 0.7.4
Supabase:
- Supabase Vector Database – Built on PostgreSQL + pgvector
- pgvector documentation
- Customer migrations: Firecrawl switches from Pinecone to Supabase, Berri AI migrates from AWS RDS to Supabase
Real-World Case Studies
Instacart Migration:
- How Instacart Built a Modern Search Infrastructure on Postgres (May 2025) – Official engineering blog
- Instacart Consolidates Search on PostgreSQL (InfoQ, August 2025)
- Key Results: 80% cost savings, 10x reduction in write workload, 6% drop in zero-result searches
Technical Resources
pgvector Project:
- pgvector on GitHub – Official open-source repository
- Latest version: 0.8.0 (November 2025)
- 10,000+ GitHub stars
Performance Benchmarks:
- Postgres + Vector Search: Complete Guide (2025) – Comprehensive benchmarking
- pgvector Benchmarks vs Specialized Databases (September 2025)
Sanjeeva Kumar is a Senior Oracle DBA with 20+ years experience . He writes about database systems, AI infrastructure, and pragmatic architecture at dbadataverse.com.
2 thoughts on “Do You Actually Need a Vector Database? Probably Not”