In our last few blogs we have explained what is BigData, How Hadoop evolved & MapReduce workings. In this blog we will see the philosophy of MapReduce.
The Philosophy:
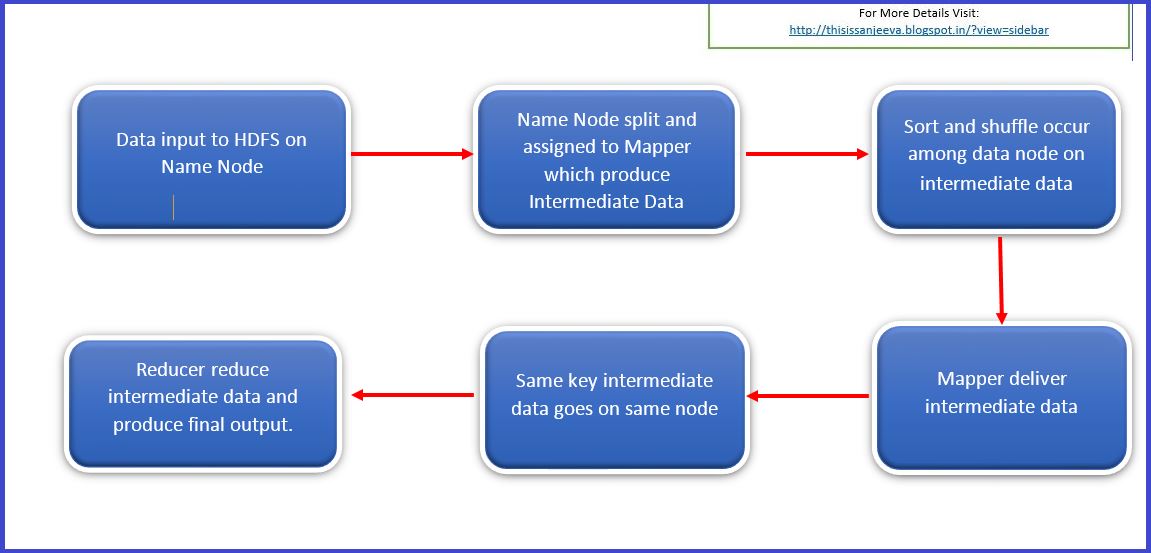
The philosophy of MapReduce internals workings is straight forward and can be summarized in 6 steps.
The smaller, the better, the quicker:
Whatever data we provide as input to Hadoop, it first splits these data into smaller no of pieces.
Typical Size of data:
For this division into pieces, the typical size of data split is limited to 64MB.
For example, a file of 1 TB is arrived to process on data node, this file will be split into 16384 pieces.
The data distribution over data nodes:
Let’s understand the impact of splitting of data over Number of Data node in HDFS cluster.
The simple calculation to split 1.2 TB of data:
Default Size: 64 MB
Total Data Size: 1048576 MB (1 TB)
No of split: 1048576/64 = 19660.8
The Explanations:
This means if you have 100 nodes (data node) HDFS cluster, using default data size, every node has to process 197(~196.08) data pieces. However, the size of the last data piece will not be exactly 64MB. It would be 51 MB.
If you increase the size of data piece to 512, it has to pick only 25 (~24.57) pieces. In this case size of last data piece would be 307MB.
With this adjustment of the size of the data, we can put a proper load to the data node in our cluster. This will impact the overall processing time.
Infographics:
The chart depicts comparison graph on the number of piece over number of data nodes.

The configurations:
Hadoop does provide a way to implement this decision of changing size of the data and hence the no of pieces to be processed by each data node.
This can be achieved by modifying configuration file hdfs-site.xml for property dfs.block.size.
Name Node Controls:
Which data node (DN) will process which piece of data file is absolutely decided by Name Node (NN) of HDFS cluster and we don’t have any control over it. The NN does a track of same.
Overtaking a down data node:
If any DN is not responding (for example, DN-78 out of 100 DN) for a specified duration, the pieces of data assigned to un-responsive data node (DN-78) will be distributed back to all other data nodes in the cluster.
Re-availability of a down data node:
Whenever, the un-responsive data node is back in the cluster, Hadoop immediately does not try to re-assign the task.
Hadoop keeps this node as redundant and in case of further failure of any other node (for example, DN-31 out of 100 nodes), DN-78 will be used by NN.
Next will be on Fault tolerance, coming soon.